
SQL
postgre SQL
cmd
docker ps 查看容器列表 docker exec -it p1 bash
如果用postgres用户连接数据库,则不用输入密码 即psql -U postgres 即可
psql -U user -d db_name -h 127.0.0.1 -p 5432
数据库操作:
\l 查看数据库列表 \c 切换数据库 create database db1 建库 drop database db1 删除数据库 createdb -U postgres mydb 在shell直接建库
SQL
按照功能不同可以分为以下几类

DDL:用于定义数据库对象,例如数据库、表、列
DML:对数据库中的记录进行增删改
DQL:查询数据库中的记录
DCL:定义数据库的访问权限和安全级别
常用关键字如上图所示
注意,MySQL对大小写不敏感,即不区分大小写,但是变量一般大写以便于区分 左上角的《新建查询》后我们可以在窗口输出各种SQL语句(就像在Mysqlshell一样)
MYSQL
mysqlsh进入mySQL-shell工具
此工具的命令都是以****开头的
bash中输入mysqlsh启动,也可以在VScode中找到mysqlsh
在输入\connect root@localhost连接
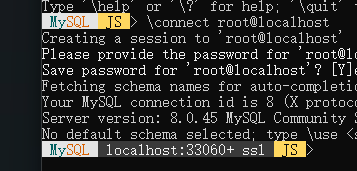
出现MySQL与JS代表进入成功
出现图片所示灰色部分表示连接到本地的mysql服务器了
use name来使用一个数据库,
JS表示当前语言,M-S支持JS、py、和SQL三种语言,切换语言\dialect
概念:
- 外码:是指一个表(称为从表或参照表)中的一个字段或字段组合,它的取值必须参照另一个表(称为主表或被参照表)中的主码(Primary Key)或候选码。
- 字段/变量/列:字面意思
- 查询脚本文件:一般以.sql结尾
语法:
首先默认数据类型是列,对象是行

1.数据库
注意:可以使用navicat等图形化GUI工具,这样不用手动输入指令创建数据库
show database; //在当前目录下查询现有数据库
CREATE DATABASE database_name; //创建数据库
drop db_name //删除数据库
当表名/变量名 属于SQL 保留字,应加上双引号
在 SQL 中,所有文本/日期/字符串常量必须用单引号 ' 包裹。否则数据库会把它当成列名或变量名
2.导入导出
导入数据:
mysql -u root -p game < game.sql
root为用户名,game为输入数据库名,game.sql为输入文件名字
输入后需要输入密码,没有错误则为导入名称
※3.创建表
定义数据类型
先选择一个数据库:use db_name;
绝大多数的sql都遵循以下标准:
CREATE TABLE [IF NOT EXISTS] 表名 (
-- 1. 定义列(Column Definition)
列名1 数据类型 [列级约束] [默认值] [注释],
列名2 数据类型 [列级约束] [默认值] [注释],
-- 2. 定义约束(Constraint Definition)—— 写在最后
[表级约束]
) [表选项(如存储引擎、字符集)];
最简单的:
//创建一个表 括号中时字段名称和数据类型,注意逗号的使用
create table tb_name (
id INT,
name VARVHAR(100), //字符串 大小100个字符
level INT,
exp INT,
god DECIMAL(10,2) //长度为10,保留两位小数的十进制数值 DECIMAL 用于存储准确精度防止精度丢失
)
数据类型:
整数类型:tinyint smallint int bigint 反别对应1~8个字节的储存空间 INTEGER 存储不带小数点的整数
浮点数:float double 对应4、8个字节不同精度的浮点数 NUMERIC 存储带小数点的精确数字 NUMERIC(10,2)总共10位,其中2位小数
时间:date time datetime timestamp 对应:日期 时间 日期时间 时间戳
以下是pgsql的格式示例
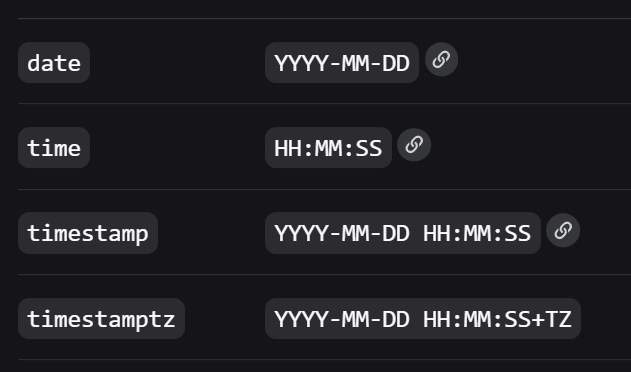
字符串:CHAR(定长) VARCHAR(最大可存的字符,可变长) TEXT BLOB
描述表的结构:DESC tb_name
约束:
为**保证数据完整性(Data Integrity)**而实施
| 序号 | 关键字 | 归属类别 |
|---|---|---|
| 1 | NOT NULL 强制该列必须有值,插入时禁止为空。也有NULL但是一般不用。 | 域完整性 |
| 2 | **DEFAULT **当插入未指定值时,自动填入预设的默认值。 | 域完整性 |
| 3 | CHECK | 域完整性 |
| 4 | UNIQUE 唯一键:确保该列(或组合)的值在该表中不重复 | 实体完整性 |
| 5 | PRIMARY KEY 主键 | 实体完整性 |
| 6 | FOREIGN KEY 外键 | 引用完整性 |
| 7 | INDEX (唯一属性) | 隐含物理约束 |
| 8 | TRIGGER | 用户自定义完整性 |
| 9 | DOMAIN | 标准高级特性 |
| 10 | EXCLUSION | PostgreSQL 专属 |
| 11 | ASSERTION | 标准未实现特性 |
| 12 | WITH CHECK OPTION | 视图约束 |
CONSTRAINT LLZ_pk_emp PRIMARY KEY (empno),
FOREIGN KEY (mgr) REFERENCES llz_emp(empno) ON DELETE SET NULL,
FOREIGN KEY (deptno) REFERENCES llz_dept(deptno) ON DELETE SET NULL
4.Alter -> 修改列
以及Delete、Update、Drop用法
D::删除列/行 U:修改数据(行) D:删除关系
-- 修改数据类型
Alter table tb_name MODIFY COLUMN name VARCHAR(200);
//表示修改表(tb_name)中的"name"列,被操作的对象是 表和列 操作方式是修改数据类型
-- 重命名
Alter table tb_name RENAME COLUMN name to nick_name;
-- 添加数据类型
ALTER TABLE tb_name ADD COLUMN last DATETIME ;
-- 此时last是新添加的字段名,DATETIME为数据类型
-- 删除某个字段(列)
ALTER TABLE tb_name DROP COLUMN last ;
-- 删除整个表格
DROP TABLE tb_name ;
-- 删除特定情况的数据(行)
DELETE FROM player where gold = 0;
-- 想要修改某个数据具体值
UPDATE tb_name set level = 1 where name = "114"
-- 想要某个数据类型在创建时写入默认值:
ALTER TABLE player MODIFY LEVEL INT DEFAULT 1 -- 默认LEVEL认值为1
-- 除DEFAULT还可以有FULL、NOT FULL、COMMENT 'infor',UNIQUE不能写在MODIFY COLUMN
-- 修改约束
ADD CONSTRAINT unique_ename UNIQUE (ename);
//若是把后面的where语句去掉,则会把整个表的数据修改,使用","连接可以修改多个值
//关键字table 、 xxx COLUMN
//ON DELETE SET NULL; 父表删除时子表相应部分设为 NULL ,同时子表数据不能定义为NOT NULL
//而 ON DELETE CASCADE;当父表(主表)的某一行被删除时,数据库会去子表找到引用了该行的所有记录,物理删除那些数据行。
//而当 CASCADE 在 DROP CONSTRAINT 后面则只删约束,不删数据,因为作用对象是数据库结构
关于修改约束时的约束名:
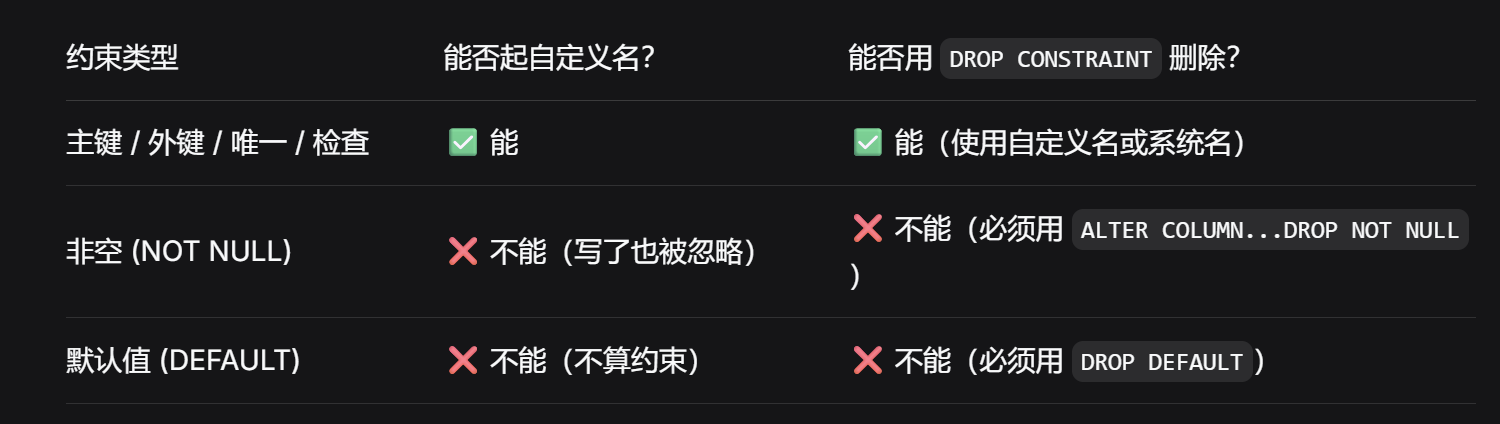
是否在alter中添加约束需要ADD CONSTRAINT [约束名] [约束]而在创建表定义约束的时候不用,直接在创建语句末尾加入CONSTRAINT [约束名] [约束]语句即可
当然 CONSTRAINT [约束名]可以省略,让系统自动帮你生成
添加主键
假设表没有主键:则可直接添加主键/复合主键
-- 假设表 employees 已有,为 employee_id 列添加主键
ALTER TABLE employees ADD PRIMARY KEY (employee_id);
-- 为多个列添加复合主键
ALTER TABLE order_items ADD PRIMARY KEY (order_id, product_id);
-- 指定约束名添加主键
ALTER TABLE employees ADD CONSTRAINT pk_emp_id PRIMARY KEY (employee_id);
删除主键
Mysql:表只有一个主键,无需指名
ALTER TABLE employees DROP PRIMARY KEY;
PgSQL/Pracle:必须使用约束名删除。如果没起名需要先查询
-- 如果你当初没起名,系统会自动生成一个(如 employees_pkey),需先查询
ALTER TABLE employees DROP CONSTRAINT pk_emp_id;
-- 查询
添加外键
一个表的外键必须是另一个表的主键
首先要确保子表的字段类型和长度与父表主键完全一致。
-- 在 orders 表中添加 customer_id 外键,引用 customers 表的 id
ALTER TABLE orders
ADD CONSTRAINT fk_customer
FOREIGN KEY (customer_id) REFERENCES customers (id);
删除外键
My:必须使用 DROP FOREIGN KEY 加上约束名。
ALTER TABLE orders DROP FOREIGN KEY fk_customer;
Pg/SQL/Ora:统一使用 DROP CONSTRAINT 加上约束名。
ALTER TABLE orders DROP CONSTRAINT fk_customer;
-- 查看有哪些外键引用了该表的主键,有的话就接触约束:CASCADE
ALTER TABLE orders DROP CONSTRAINT fk_customer CASCADE;
注:如果主键正被子表的外键引用,直接删除主键会报错。需先执行删除子表外键的操作
外键使用
当一个属性有外键约束后,不需要特定才做引入父表中的数据,直接写入值即可,是否正确让数据库自动帮你把关。即有外键约束后每插入一个数据会在主表中检测一次,数据库通过匹配这个值,来间接关联到那一行,此时外键存的是父表主键的值的副本。
另外,父表的主键默认有索引。数据库相当于在做一次 O(log n) 的索引查找,而不是全表扫描。
5.查看和插入数据
INSERT插入数据
插入数据,不是增添列(添加数据类型),而是增加对象(增加行),基本语法:
-- 基本语法
INSERT INTO db_name(id,name,level,exp,gold)VALUES(1,"sc",1,1,1);
-- 多条插入
INSERT INTO db_name(id,name)VALUES(2,"114")(3,"514")
-- 此时没有默认值的数据类型是NULL,需要set默认值见上
省略:如果VALUE后的数量与表中所有数据对得上(总的数量一样),则VALUES前的括号可以省略
多条插入:也可以一次性插入多条数据(行),V后面写入多个括号即可
select查找数据
*则表示查询所有的列,跟特定数据类型时只会展现特定的列,数据类型用",“连接
-- select选择要查询的列 *则表示查询所有的列 from后面根要查询表的名称
select * from tb_name;
-- SELECT后列出要查询的列 FROM后列出有要select的表,然后再在后面加要求
SELECT ENAME, JOB, HIREDATE, SAL FROM EMP WHERE DEPTNO = 10;
“加要求”包括:LIKE语句,WHERE语句
聚合函数是要SELECT的对象经过(聚合函数)处理后的样子,LIKE和WHERE是对象的特征
MODIFY COLUMN表示修改列,后面表示需要修改的列名和数据结构
UPDATE修改数据
UPDATE player set level = 1 where name = ""; -- 修改特定值,name可换成其他主键
UPDATE player set level = 1,gold = 0; -- 去掉where 修改全部
DELETE删除数据
-- 删除整个表格
DROP TABLE tb_name ;
-- 删除特定情况的数据(行)
DELETE FROM player where gold = 0;
※SELECT
WITH 新表名 AS(
SELECT 选择查询返回的新表
)
SELECT (DISTINCT) 属性,属性 FROM 表 (缩写名)(AS 别名) (多表查询 xxx JOIN) WHERE/ LIKE 满足查询的要求的记录 GROUP BY 根据什么分组
HAVING 筛选分组后的数据 ORDER BY 属性名 排序顺序 LIMIT 选择展现数量
EXCEPT -- EXCEPT返回第一个查询中存在但第二个查询中不存在的行。
起别名不用引号,做比对用单引号,和关键字冲突用双引号
DISTINCT
在SELECT后使用DISTINCT去除重复记录(因为删除列之后可能会有两个相同的行)
属性:
1.正常列名,可以起别名
2.可以是子查询
3.聚合函数(可以不用分组直接使用)
-- 1.
r.name AS 零售商名称,
-- 2.
(
SELECT COUNT(*)
FROM "Order" o
WHERE o.rID = r.rID
AND o.type = '普通订单'
) AS 普通订单数量,
-- 3.
AVG (price)
-- 聚合函数也可以用DISTINCT 如:
SELECT COUNT(DISTINCT p.pID) FROM
多表查询
xxx JOIN 表1 (缩写名1) ON 连接条件
xxx JOIN 表2 (缩写名2) ON 连接条件
xxx有INNER / LEFT /RIGHT
WHERE/like
where:
可以使用AND 、OR 、 IN 、EXISTS、NOT、BETWEEN AND、正则表达式来寻找行
不能用聚合函数,Having才能用聚合函数
where后也可以跟子查询
-- 判断某个字段的值,是否等于子查询返回结果中的任意一个值。
WHERE Sdept IN (SELECT Sdept FROM Student WHERE Sname = '张三');
-- 比较运算符 返沪一个聚合查询的结构
WHERE Grade > (SELECT AVG(Grade) FROM SC);
-- 带 EXISTS 谓词的子查询 返回是否存在1/0
WHERE EXISTS (SELECT * FROM SC WHERE SC.Sno = Student.Sno AND Cno = '001');
-- ANY/ALL 返回多个行
WHERE Grade >= ALL (SELECT Grade FROM SC WHERE Cno = '002');
like:
模糊查询, %表示任何字符,_表示一个字符
LIKE '%王_'
GROUP by
根据什么分组,所有出现在 SELECT列表中的列,如果不是聚合函数的参数,则必须出现在 GROUP BY 子句中
可以和WHERE配合,WHERE过滤行,GROUP BY将剩下的行分组,HAVING将
HAVING
分组之后过滤组,筛选分组后的数据,此时要使用聚合函数,如
HAVING AVG(salary) > 5000;
ORDER BY
降序DESC 升序ASC 可以用数字表示列数
ORDER BY 5/price DESC/ASC
注意,查询中第一个查询的排在最上面,所以升序从上往下递增,最上面的是最小的,降序同理
LIMIT
LIMIT 3 -- 只取前三条
LIMIT 3,3 -- 返回第四到第六名 第一个三表示偏移量 第二个表示往后取三个
示例:
SELECT DISTINCT -- 这里DISTINCT在分组后其实冗余(因为GROUP BY已确保唯一),但为了演示语法我保留它
n.nID AS 管理员编号,
n.nName AS 管理员姓名,
COUNT(bs.bsID) AS 管理实体书总数
FROM BookSKU bs
INNER JOIN BookPub bp ON bs.bpID = bp.bpID
INNER JOIN Shelf s ON bs.sID = s.sID
INNER JOIN Librarian n ON s.nID = n.nID
INNER JOIN Room r ON s.rID = r.rID
WHERE r.rName = '信息技术图书室' -- 位置条件
AND bp.bpTitle LIKE '%数据%' -- LIKE条件
AND bs.bsRegTime >= '2026-01-01'
GROUP BY n.nID, n.nName
HAVING COUNT(bs.bsID) >= 2 -- 分组后筛选
ORDER BY COUNT(bs.bsID) DESC
LIMIT 2;
6.导出导入数据
不同的sql数据库有着不同的语法,仅列出Mysql和pgsql
Mysql
# 导出整个数据库
mysqldump -u username -p database_name > backup.sql;
# 导入数据库
mysql -u username -p database_name < backup.sql;
# 仅导出表结构,不含数据(-d 参数)
mysqldump -u username -p -d database_name > structure.sql;
pgsql
# 导出数据
bcp database_name.dbo.your_table out data.csv -c -t, -S server_name -U username -P password
# 导出查询结果
bcp "SELECT * FROM your_table" queryout data.csv -c -t, -S server_name -U username -P password
7.WHere
使用where子句进行查询
用于查找满足指定标准的记录
有时候需要正则表达式
//where
-- 查找经验在特定区域的player
SELECT * FROM player WHERE level > 1
SELECT * FROM player WHERE level > 1 AND level < 5
-- 优先级NOT > AND > OR,可以用括号改变优先级,可以用IN查找特定值的数据
SELECT * FROM player WHERE (LEVEL > 1 OR exp > 1)
SELECT * FROM player WHERE level IN (1,3,5) //查找为1,3,5的玩家
SELECT * FROM player WHERE NOT BETWEEN 1 AND 10 //等级不在1 ~ 10的玩家
匹配正则表达式:
有时要求比较复杂,我们使用正则表达式
使用 REGEXP 表示使用正则表达式
-- 注意 % 和 _是like中才有的,正则表达式中没有
-- 则查找姓王且为两个字的玩家
SELECT * FROM player name REGEXP '^王.$'
-- 查找名字带王的人
SELECT * FROM player name REGEXP '王'
详情如下:

8.like模糊查询
注意:like 后要跟两种通配符之一: %表示任何字符,_表示一个字符
//LIKE模糊查询
-- 则模糊查询可以查找到名字是“王”前有任意个字,“王”后有两个字的玩家
SELECT * FROM player NAME LIKE '%王__'
-- 查找姓“王”的玩家
SELECT * FROM player NAME LIKE '王%'
-- 查找名字里有“王”的玩家
SELECT * FROM player NAME LIKE '%王%'
tips:null值相关
NULL与任何值都不相等,包括他本身
而另外,空字符串” “本身与NULL是不一样的
-- 查找信息为空的值 注意不能用name = NULL NULL和任何值都不相等
SELECT * FROM plaer where email = NULL; -- 会得到一个空结果集
SELECT * FROM plaer where email is NULL; -- √
SELECT * FROM plaer where email <=> NULL //its all OK
-- 有时候是空字符串,其与NULL是不一样的,空字符串使用" = "判断
SELECT * FROM player where email = '' or email is NULL //its OK
9.ORDER BY
使用Order By对查找结果进行排序
-- 默认升序排列
SELECT * FROM player ORDER BY level;
-- DESC 降序排列
SELECT * FROM player ORDER BY level DESC; //降序
-- 在优先按照level升降排列的情况下按照exp升序排列
SELECT * FROM player ORDER BY level DESC,exp ASC;
-- 且可以使用列数进行排列,假设level为第五列 则有
SELECT * FROM player ORDER BY 5 DESC,exp ASC;
升序:

效果如:
| level | exp |
|---|---|
| 99 | 4 |
| 99 | 80 |
| 99 | 93 |
10.聚合函数
聚合函数,内部只做一件事:遍历数据行,维护一个中间状态(累加器/计数器/极值缓存)。即输入多行数据,处理数据,然后输出只有一行或每个分组一行的结果
使用聚合函数对某列(某个数据类型)进行计算
如平均值、中位数、最大最小值等
对查找结果进行计算
-- 查找玩家数量
SELECT COUNT(*) FROM player;
-- 查找等级平均值
SELECT AVG(LEVEL) FROM player
以下为常用聚合函数:

11.分组
使用GROUP BY
-- 按性别分组
SELECT sex,count(*) from player group by sex;
-- 此时SELECT返回两列:s、c,from表示从player表,sex表示按照列的值进行分组
-- 得到的结果是所有 sex 相同的行会被归入同一个组,然后对每个组执行 count(*) 聚合计算。
SELECT level,count(level) from player group by level;//看每个等级各有多少个玩家
注意:所有出现在 SELECT 列表中的列,如果不是聚合函数的参数,则必须出现在 GROUP BY 子句中
由于level本身就是分组的依据,所以可以在select中。另外,在Mysql的宽松模式下,非分组列进入select中时,可能不报错,并且会随机选择该分组内的某个值
当需要依据多个条件进行分组时:
-- 1
SELECT
department_id,
job_id,
AVG(salary) AS avg_salary
FROM employees
GROUP BY department_id, job_id;
-- 2 同时使用where和having 两者具体使用在下面
SELECT
department_id,
job_id,
AVG(salary) AS avg_salary
FROM employees
WHERE job_id > 2 -- 分组前先筛选出 job_id > 2 的行
GROUP BY department_id, job_id
HAVING AVG(salary) > 5000; -- 分组后筛选平均工资 > 5000 的分组
having:筛选分组后的数据
having主要用途是与 GROUP BY 配合,在部分数据库(如My、pg)中也可以单独使用:此时它将整个表视为一个分组,对聚合函数的结果进行过滤
-- 查询数量大于4的各个等级的数量(不是等级比4大的玩家)
SELECT level,count(level) from player group by level having count(level)> 4
-- 降序排列
SELECT level,count(level) from player group by level having count(level) > 4 ORDER by count(level) DESC;
-- 单独使用对聚合函数过滤
-- 检查所有员工的平均工资是否大于 5000
SELECT AVG(salary) AS avg_sal
FROM employees
HAVING AVG(salary) > 5000;

WHERE不能包含聚合函数!!!
SUBSTR:
截取某个数据类型的变量长度
SUBSTR(name,1,2) -> 从name的第一个字开始截取,长度为2
LIMIT:返回前几名
SELECT level,count(level) from player group by level having count(level) > 4 ORDER by count(level) DESC
/代码如having处,省略,注意必须要配合 ORDER BY 使用
LIMIT 3 -- 只取前三条
LIMIT 3,3 -- 返回第四到第六名 第一个三表示偏移量 第二个表示往后取三个
12.重复记录处理
包括去重、合并、交集、差集
在SELECT后使用DISTINCT去除重复记录
如果想要合并两条查询记录,使用UNION进行合并,并且UNION会默认去除重复的记录,如果不想重复的记录被删除则使用 UNION ALL
使用INTERSECT查询两个结果的交集,使用位置同UNION
使用EXCEPT查找差集 A EXCEPT B -> A - B
-- 查询所有玩家的性别
SELECT DISTINCT sex from player;
SELECT * FROM player WHERE level between 1 AND 3
UNION -- UNION合并
SELECT * FROM player WHERE exp between 1 AND 3
13.子查询
子查询就是把一个查询的结果作为另一个查询的起始条件
使用as对查询起一个别名
SELECT AVG(level) from player;
select * from player where level > (SELECT AVG(level) from player)
-- 使用 as 和 round
SELECT level,ROUND((SELECT AVG(level) from player)) as average;
tips:ROUND( ) -> 对该数据四舍五入
还可以用子查询创建新表
-- 创建新表
create table new_player select * from player where level < 5;
-- 插入数据
insert into new_player select * from player where level BETWEEN 6 and 10;
使用select exists( )判断查询是否有结果 -> 返回0没有结果 返回1有结果
标量子查询
定义:只返回“一个值”(一行一列)的子查询。这个值可以是数字、字符串、日期等。
如果子查询没有匹配到数据(返回空),标量子查询会返回 NULL。参与运算时需留意 NULL 的影响。
WITH
WITH相当于先定义一个临时的“视图/表”(只在本次查询中生效),然后主查询可以像使用普通表一样多次引用它。
WITH SAL_GRADE AS (
SELECT GRADE, LOSAL, HISAL FROM SALGRADE
)
SELECT e.ENAME, e.SAL, (
SELECT s.GRADE FROM SAL_GRADE s WHERE e.SAL BETWEEN s.LOSAL AND s.HISAL
) AS GRADE
FROM EMP e;
常用语句:
在WHERE后添加子查询,如:
SELECT Sno, Sname
FROM tb_name
-- IN 谓词 子查询返回多个行
WHERE Sdept IN (SELECT Sdept FROM Student WHERE Sname = '张三');
-- 比较运算符 返沪一个聚合查询的结构
WHERE Grade > (SELECT AVG(Grade) FROM SC);
-- 带 EXISTS 谓词的子查询 返回是否存在1/0
WHERE EXISTS (SELECT * FROM SC WHERE SC.Sno = Student.Sno AND Cno = '001');
-- ANY/ALL 返回多个行
WHERE Grade >= ALL (SELECT Grade FROM SC WHERE Cno = '002');
ANY/ALL指 要求查询对象(如Grade)要符合条件全部/至少有一个(>=)
在Select语句中查找
SELECT
r.name AS 零售商名称,
(
SELECT COUNT(*)
FROM "Order" o
WHERE o.rID = r.rID
AND o.type = '普通订单'
) AS 普通订单数量,
(
SELECT COUNT(*)
FROM "Order" o
WHERE o.rID = r.rID
AND o.type = '加急订单'
) AS 加急订单数量
FROM Retailer r;
14.表关联
15.索引
16.视图
17.主键外键
外键
查询某表主键名:
- 列名:标识“存储什么数据”(物理存储单元)
- 约束名:标识“用什么规则管理数据”(逻辑规则对象)
它们是完全不同的数据库对象,一个列上可以有多个约束,而当主键为多个列时只能用一个约束名,删除约束时,必须使用约束名,而不是列名
-- 此种会给出约束的完整定义,结果包含名字 + 具体是哪个字段做主键
SELECT conname, pg_get_constraintdef(oid) AS constraint_def
FROM pg_constraint
WHERE conrelid = 'table_name'::regclass
AND contype = 'p';
-- 只查询 conname(约束名称),只有名字,没有变量名(或者说字段)
SELECT conname
FROM pg_constraint
WHERE conrelid = 'llz_dept'::regclass AND contype = 'p';
-- 修改主键
-- 1. 删除现有主键约束(假设约束名为 old_key)
ALTER TABLE emp DROP CONSTRAINT old_key;
-- 2. 添加新主键约束到目标列(deptno) 此时CONSTRAINT new_key是该改变主键约束名
ALTER TABLE emp ADD CONSTRAINT new_key PRIMARY KEY (deptno);
外键
外键是一个表中的一列(或多列),它的值必须匹配另一个表的主键或唯一键中的值。它用来建立两个表之间的父子关系。
特性:
- 参照完整性:外键的值必须在父表中存在,或为
NULL(除非明确NOT NULL)。 - 允许重复和 NULL:外键列可以重复,也可以为空。
- 可建立多个:一张表可以拥有多个外键,引用不同父表。
- 表级依赖:父表必须先创建;删除表时需先删除子表或先移除外键约束。
构建例子:
-- 父表
CREATE TABLE classes (
class_id INT PRIMARY KEY,
class_name VARCHAR(50)
);
-- 创建时
-- 子表,定义外键
CREATE TABLE students (
student_id INT PRIMARY KEY,
name VARCHAR(50),
class_id INT,
CONSTRAINT fk_student_class -- 可选,为约束命名
FOREIGN KEY (class_id) REFERENCES classes(class_id)
);
-- 修改表时:
ALTER TABLE students
ADD CONSTRAINT fk_student_class
FOREIGN KEY (class_id) REFERENCES classes(class_id);
-- delete
ALTER TABLE students DROP FOREIGN KEY fk_student_class; -- MySQL
ALTER TABLE students DROP CONSTRAINT fk_student_class; -- (PostgreSQL/SQL Server)
作用:级联操作
当父表的主键值被更新或删除时,可以定义子表的行为。在 REFERENCES 后添加 ON DELETE 和 ON UPDATE 子句。
CREATE TABLE students (
student_id INT PRIMARY KEY,
name VARCHAR(50),
class_id INT,
FOREIGN KEY (class_id) REFERENCES classes(class_id)
ON DELETE SET NULL -- 班级删除后,学生 class_id 变为 NULL
ON UPDATE CASCADE -- 班级 ID 更新时,学生 class_id 同步更新
-- 除此之外 SET DEFAULT 变为默认值 RESTRICT / NO ACTION阻止父表的删除/更新操作保护重要参照数据不被误删
);
外键也可以由多列组成,引用父表的复合主键或复合唯一键,此处略
18.AS
主要作用是起别名(Alias),让查询结果或表引用更清晰、易读。此外,在定义公用表表达式(CTE)或创建新对象时也必不可少。
1.给列起别名:
SELECT 列名 AS 别名 FROM 表名;
别名只在查询结果的列标题中生效,不会改变原表结构。
AS 关键字可以省略,但推荐保留以增强可读性
2.给表起别名
当查询涉及多个表(尤其是多表连接、子查询),或者表名很长时,可以用 AS 给表起一个短别名,然后在查询的其他地方使用该别名。
SELECT 别名.列名 FROM 表名 AS 别名;
AS 在表别名中也可以省略,但同样建议保留
FROM orders o -- o作为order的别名
3.定义公用表表达式(如13)
WITH ... AS 结构用于定义一个临时的、可重用的结果集(类似派生表,或者说函数/函数返回值),使复杂查询更模块化。基本语法如下:
WITH 别名 AS (
-- 子查询
SELECT ...
)
-- 此时这个表已经经历了一轮筛选,并且被起了别名
-- 主查询使用这个
SELECT * FROM 别名;
19.多表查询
多表查询
内连接Inner JOIN
-- 查询每个员工及其部门名称
SELECT e.name, d.dept_name
FROM employees e
INNER JOIN departments d ON e.dept_id = d.dept_id;
-- 主表:e 被组合的表:e,此时我们可以在select后e.name AS ENAME来起别名,这样当两个表名称一样时则可以右更好的可读性
-- ON 后面跟条件,表示只有当id相同时才会被并入e表里
左/右连接
-- 左
SELECT s.student_id, s.name, sc.score
FROM students s
LEFT JOIN scores sc ON s.student_id = sc.student_id;
-- 保留了左表 students 的所有行
-- 右
SELECT s.student_id, s.name, sc.score
FROM students s
RIGHT JOIN scores sc ON s.student_id = sc.student_id;
-- 保留了右表 scores 的所有行
-- 一般主要使用左连接
区别:

FULL [OUTER] JOIN(全外连接)
返回两个表的所有行,对方无匹配时填 NULL。MySQL 原生不支持,但可用 LEFT JOIN UNION RIGHT JOIN 模拟。
还有交叉连接(笛卡尔积)和自连接
遇到NULL也要保留的情况时:
如:
SELECT
r.rName AS 图书室名称,
COUNT(CASE WHEN bp.bpPrice > 50 THEN 1 END) AS 单价超50元图书数量
FROM Room r
LEFT JOIN Shelf s ON r.rID = s.rID
LEFT JOIN BookSKU bs ON s.sID = bs.sID
LEFT JOIN BookPub bp ON bs.bpID = bp.bpID
GROUP BY r.rID, r.rName
ORDER BY r.rName;
CASE WHEN:开始逻辑判断,类似if
THEN 1:条件为真时返回的值(1)
END:结束CASE表达式
隐含ELSE:不写ELSE则数据库默认返回 NULL。这是整个技巧能成立的核心!
然后COUNT会看到类似于:1,1,NULL,NULL,开始统计
(附:
COUNT只在乎括号里是不是NULL。- 如果是
NULL,忽略;如果不是NULL(无论是1、0、'abc'还是true),都计数。
)
集合操作
UNION
将两个查询的结果合并,去除重复行
会执行隐式的 DISTINCT 操作,性能相对较低。
-- 查询所有学生的姓名和老师的姓名(合并为一列,且不重复)
SELECT column1, column2 FROM tableA
UNION
SELECT column1, column2 FROM tableB;
假设 students 有 ‘张三’, ‘李四’;teachers 有 ‘李四’, ‘王五’,则结果为 ‘张三’, ‘李四’, ‘王五’。
UNION ALL
相比UNION保留所有行(包括重复),但是性能较高
INTERSECT
返回同时存在于两个查询结果中的行(交集并去重),相当于AND逻辑
MySQL 不直接支持 INTERSECT,可以使用 INNER JOIN 或 EXISTS 模拟:
SELECT DISTINCT s.name -- 直接使用DISTINCT去除重复记录
FROM students s -- 虽然INNER JOIN逻辑是取两个表都有的部分,但是最终指向的还是s表,所以IDSTINCT s
INNER JOIN teachers t ON s.name = t.name;
EXCEPT
- 返回存在于第一个查询结果,但不存在于第二个查询结果中的行(去重),不是A - B!
- 有的数据库(如 Oracle)使用
MINUS关键字。
SELECT column1, column2 FROM tableA
EXCEPT
SELECT column1, column2 FROM tableB;
MySQL 不直接支持 EXCEPT,可以使用 LEFT JOIN + WHERE ... IS NULL 或 NOT EXISTS 模拟:
SELECT DISTINCT s.name
FROM students s
LEFT JOIN teachers t ON s.name = t.name
WHERE t.name IS NULL;
EXISTS
- EXISTS(存在):只要子查询能查出至少 1 条记录,条件就为
TRUE,外层查询就会包含该行。 - NOT EXISTS(不存在):只有子查询返回空集(0条)时,条件才为
TRUE。
例如:
SELECT r.name, r.phone
FROM Retailer r
WHERE EXISTS (
SELECT 1
FROM "Order" o
WHERE o.rID = r.rID
);
此时select 1 只是一个存在性占位符,不代表任何具体的列或数据