
计组
笔记参考:
王道计组
saurlax:https://saurlax.com/blog/principles-of-computer-composition
网盘LCX的PPT(大部分图片来源)
注:本笔记可能有错漏仅供参考,且大部分内容直接照搬,只是提取出来便于总结,有错误可以帮忙踢一脚作者(仅供参考仅供参考)
标题等级颜色对应:一二三四五级标题对应蓝红紫绿黄,红色小字是加粗
================================================================
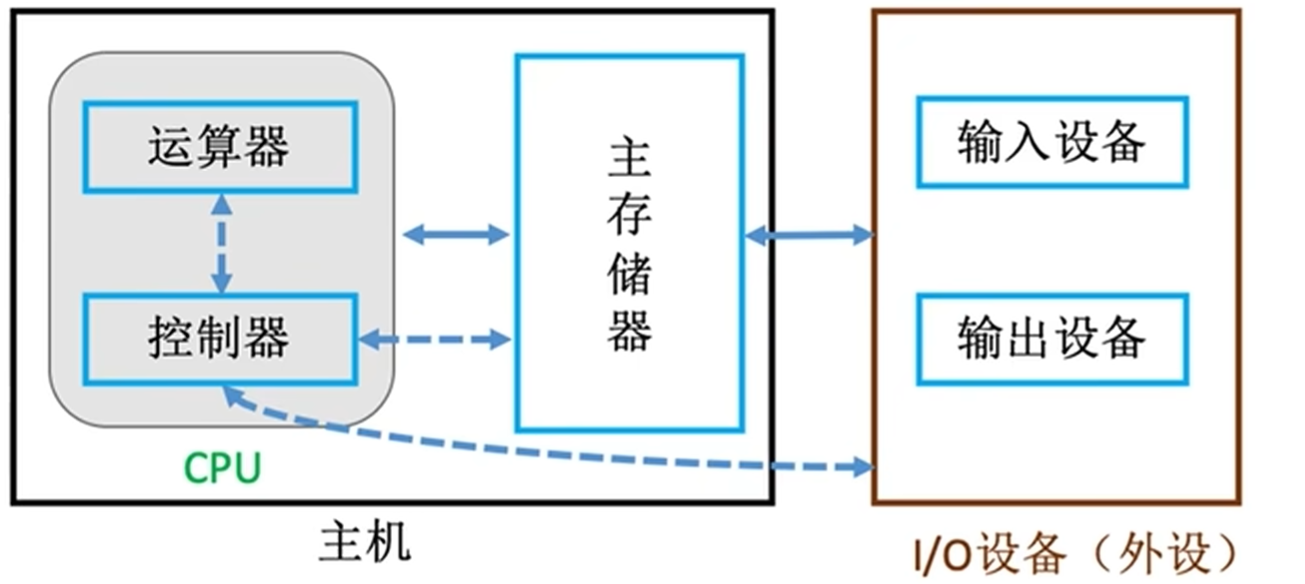
这是计算机世界的架构:
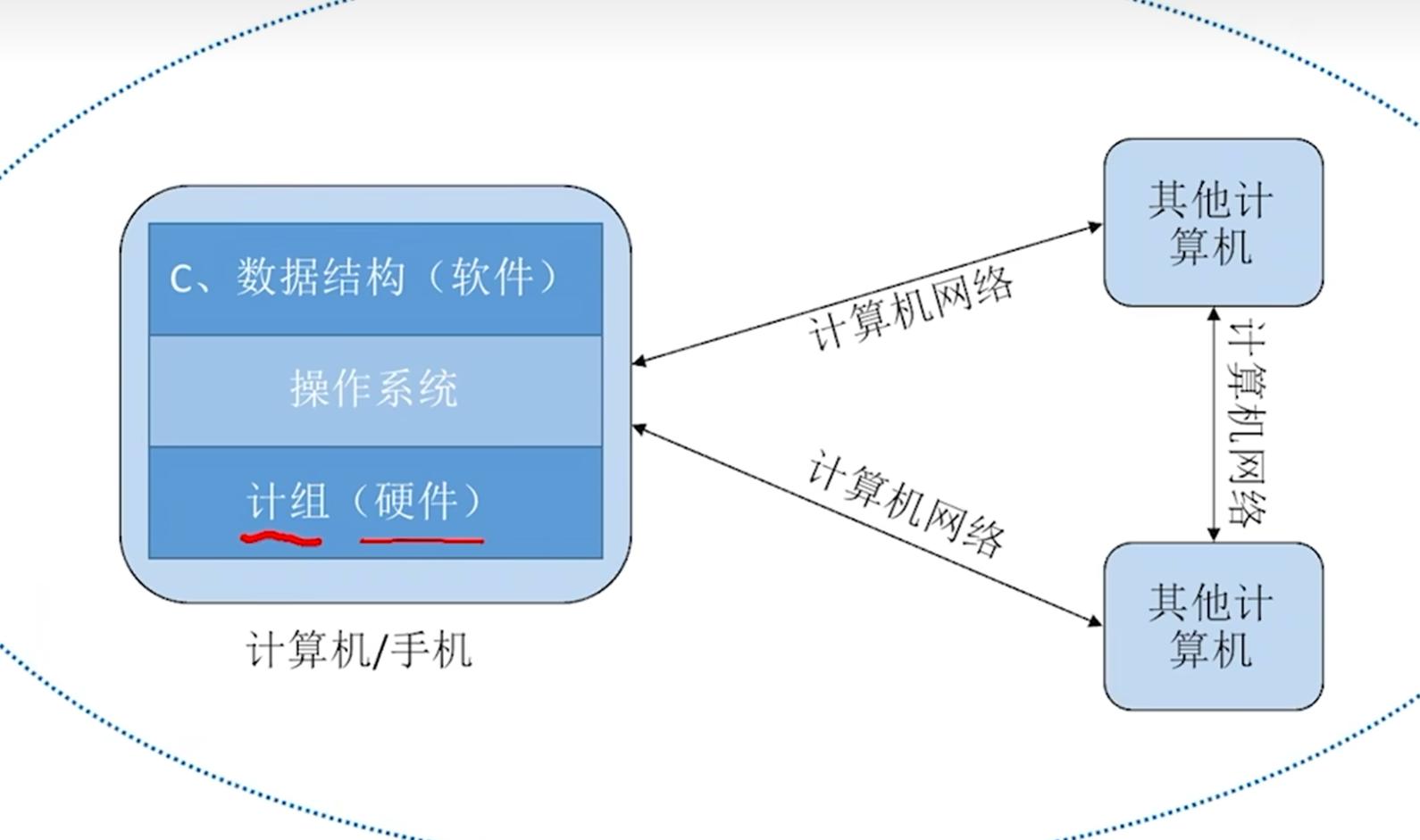
计组就是研究这些硬件在底层如何相互协调工作的
一、概论
冯诺依曼机
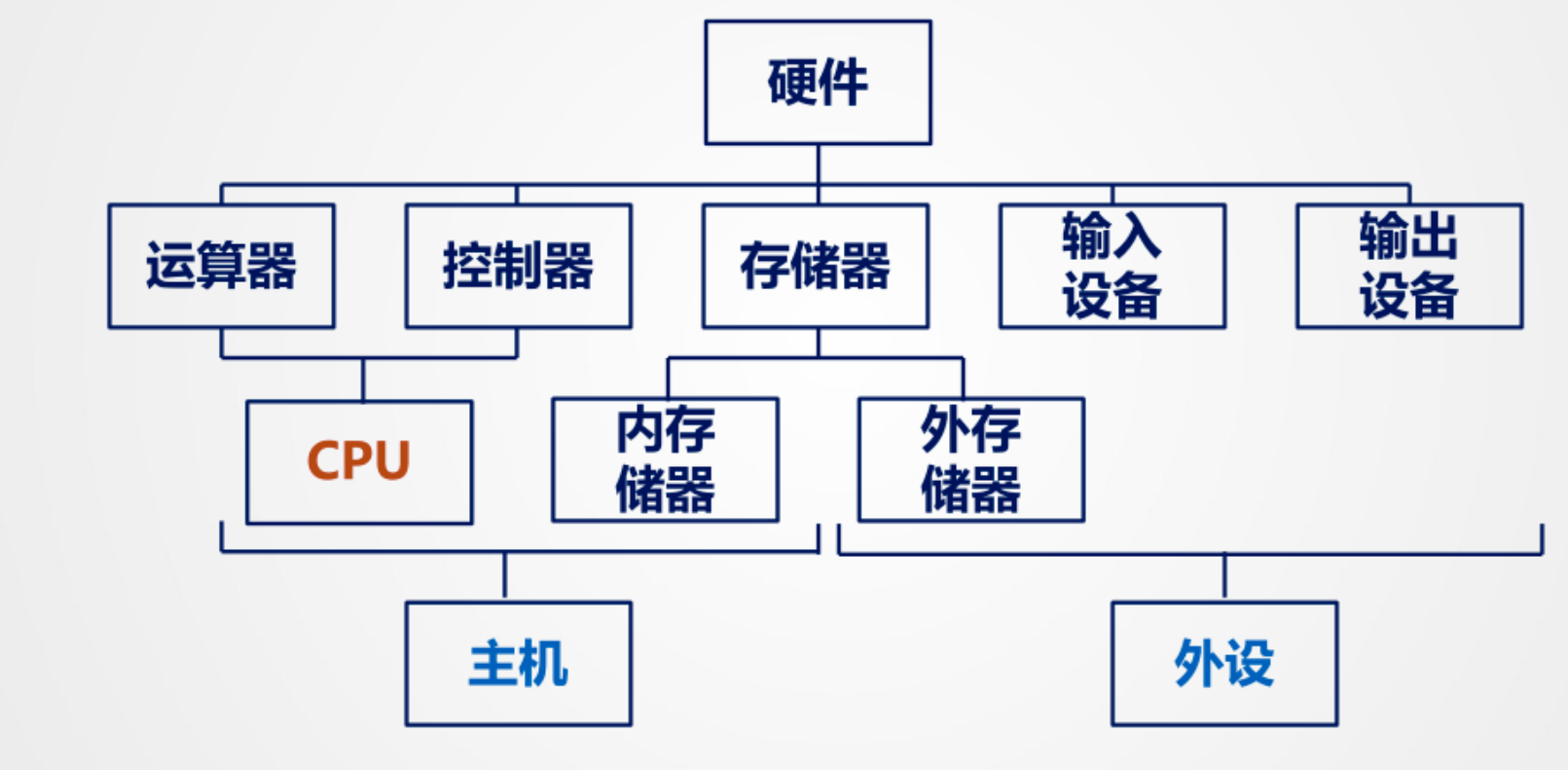
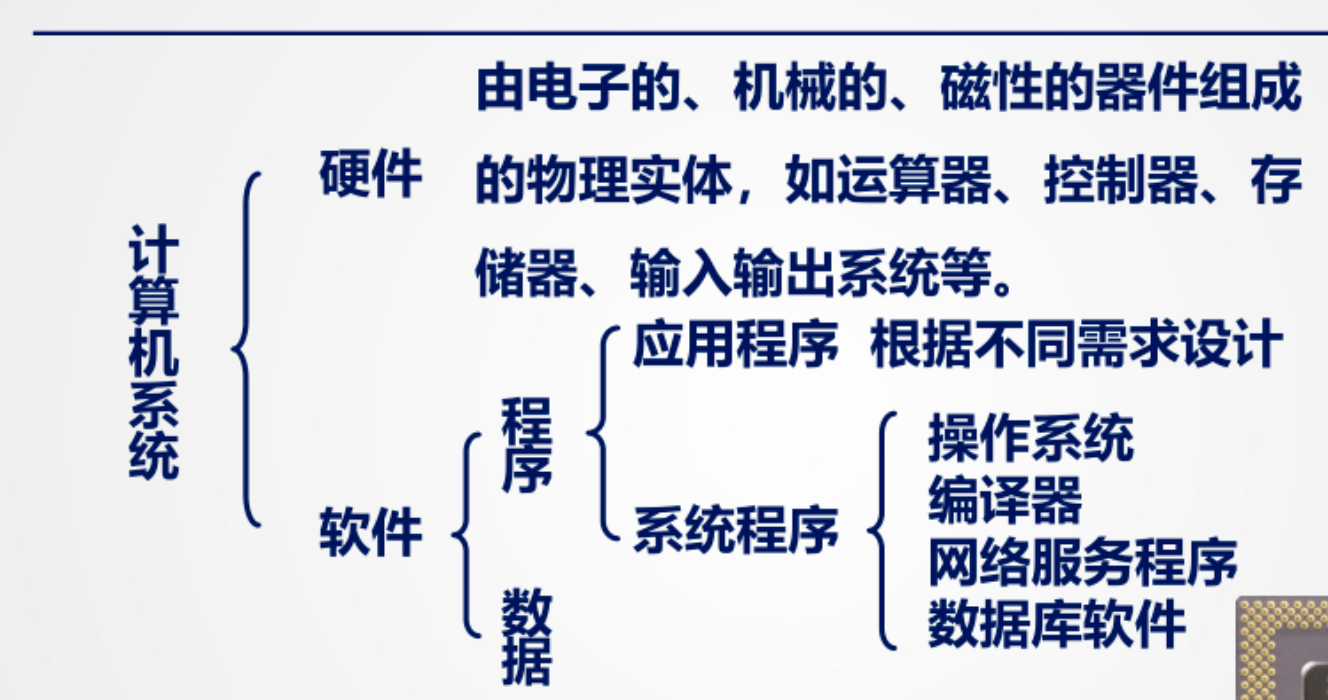
硬件:
冯诺依曼计算机由五大部件构成(现代计算机也是),后面只要学习这五个部分
- 运算器:负责算术运算和逻辑运算。
- 控制器:负责控制整个计算机系统的运行。
- 存储器:存放数据和指令。
- 输入设备:将数据输入到计算机中。
- 输出设备:将计算机处理的数据输出。
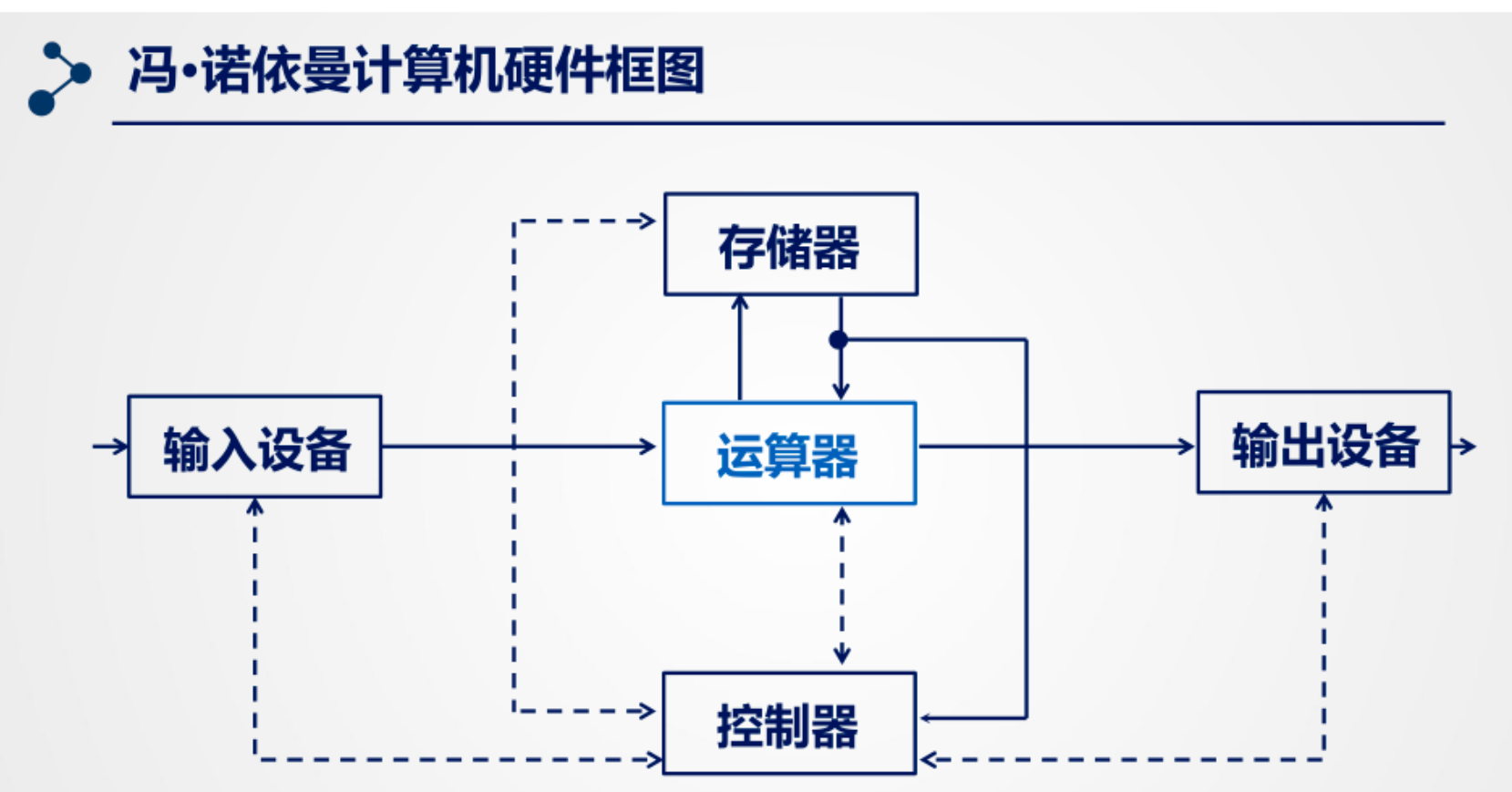
部件关系:
结构特点:
- 冯·诺依曼计算机主要由五大部件组成,分别是:运算器、控制器、存储器、输入设备和输出设备;
- 冯诺依曼体系结构的指令和数据均采用二进制码表示;
- 指令和数据以同等地位存放于存储器中,均可按地址寻访;
- 指令由操作码和地址码组成,操作码用来表示操作的性质,地址码用来表示操作数所在存储器中的位置;
- 存储程序,指令可以被存储,在存储器中按顺序存放,通常指令是按顺序执行的,特定条件下,可以根据运算结果或者设定的条件改变执行顺序;
- 机器以运算器为中心,输入输出设备和存储器的数据传送通过运算器。
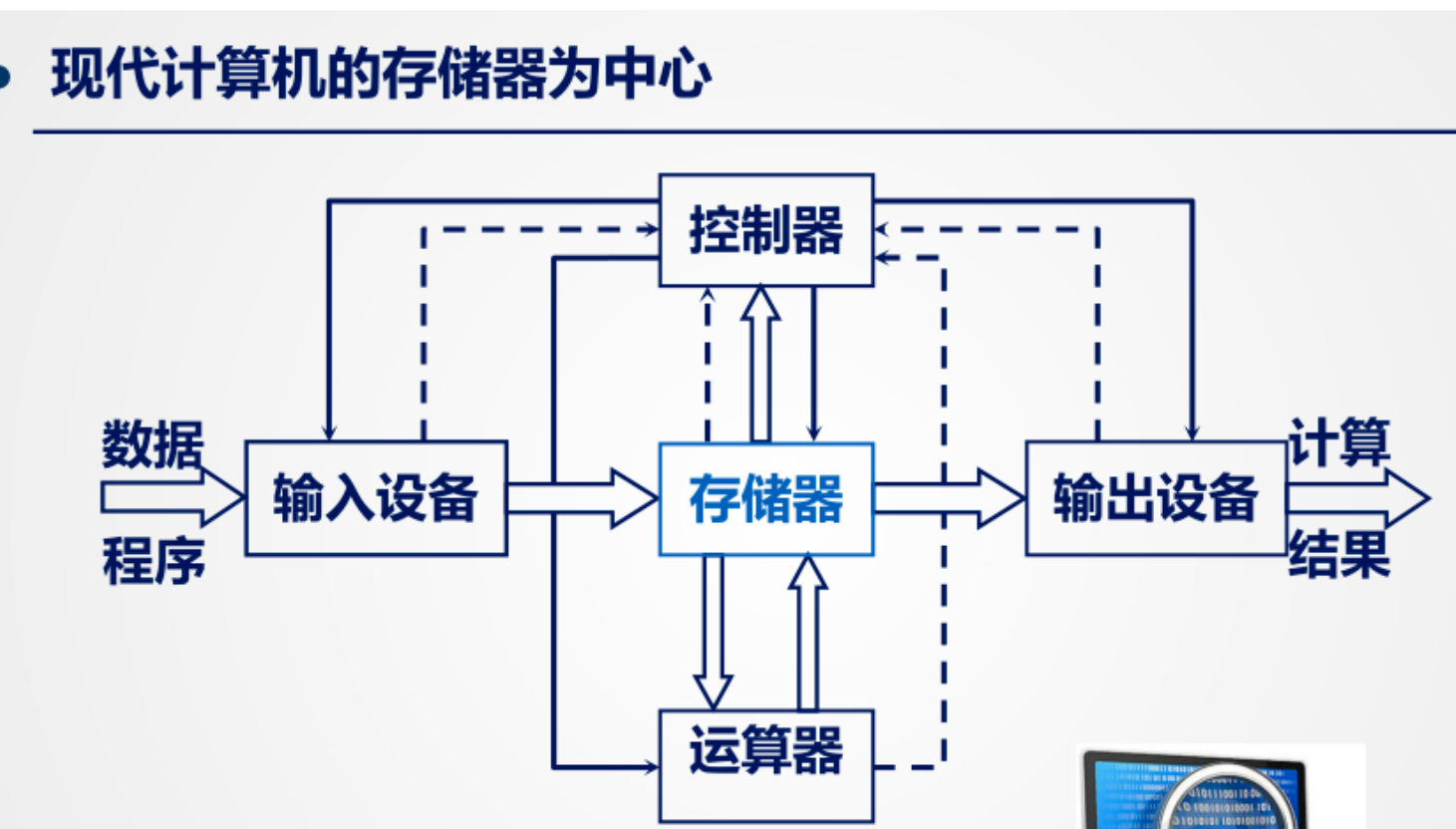
VS 现代计算机
冯诺依曼:
以运算器为中心
现代计算机
以存储器为中心,存储容量成倍扩大,需计算机处理的信息量与日俱增
软硬件:
计算机层次结构
计算机组成 与 计算机系统结构
计算机组成:实现计算机体系结构所体现的属性,描述“怎么做”的问题
计算机系统结构:程序员所见到的计算机系统的树形,描述“做什么”的问题
计算机系统层次结构:

三种不同的编程语言
高级语言:C、Py、Go
汇编语言:TEC-XP学过
机器语言:全是0和1
其他
主要术语:
- 主机:是计算机硬件的主体部分,由 CPU 和主存储器 MM 合成为主机。
- CPU:中央处理器,是计算机硬件的核心部件,由运算器和控制器组成;(早期的运算器和控制器不在同一芯片上,现在的 CPU 内除含有运算器和控制器外还集成了 CACHE)。
- 主存:计算机中存放正在运行的程序和数据的存储器,为计算机的主要工作存储器,可随机存取;由存储体、各种逻辑部件及控制电路组成。
- 存储单元:可存放一个机器字并具有特定存储地址的存储单位。具有物理意义,而字节是完全的数量概念
- 存储元件:存储一位二进制信息的物理元件,是存储器中最小的存储单位,又叫存储基元或存储元,不能单独存取。
- 存储字:一个存储单元所存二进制代码的逻辑单位。
- 存储字长:一个存储单元所存储的二进制代码的总位数。
- 存储容量:存储器中可存二进制代码的总量;(通常主、辅存容量分开描述)。
- 机器字长:指 CPU 一次能处理的二进制数据的位数,通常与 CPU 的寄存器位数有关。
- 指令字长:机器指令中二进制代码的总位数。
- MAR(Memory Address Register):存储器地址寄存器,用于存放将要访问的存储单元的地址。
- MDR (Memory Data Register):存储器数据寄存器,用于存放从存储器读出的数据或将要写入存储器的数据。
计算机硬件的主要技术指标
- 1.机器字长:指 CPU 一次能处理的二进制数据的位数,通常与 CPU 的寄存器位数有关。
- 2.运算速度:衡量运算速度主要有以下标准:
- 主频:CPU 内部振荡器的频率,通常以 MHz 或 GHz 为单位。
- 吉普森法:
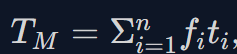 ,
其中 fi为第 i 个操作的频率,ti 为第 i 个操作的时间。
,
其中 fi为第 i 个操作的频率,ti 为第 i 个操作的时间。 - MIPS:每秒百万条指令数。
- CPI:每条指令的平均时钟周期数。
- FLOPS:每秒浮点运算次数。
- 每秒执行的百万条指令数
- 3.存储容量:存储器中可存二进制代码的总量。
- 主存容量:
- 存储单元数 MAR × 存储字长 MDR。
- 2^字节数。
- 辅存容量
- 主存容量:
阿姆达尔定律:用来衡量系统在部分资源(如处理器数量)得到改进后,整体性能能够提升多少,尤其常见于并行计算领域。
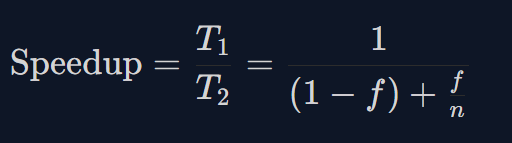
其中 T1 为在单个处理器上的执行时间,T2为在 n 个并行处理器上的执行时间, f 为原系统中需要改进的部分所占的比例, n 为改进后系统中改进部分的执行速度。
二、总线
概述:
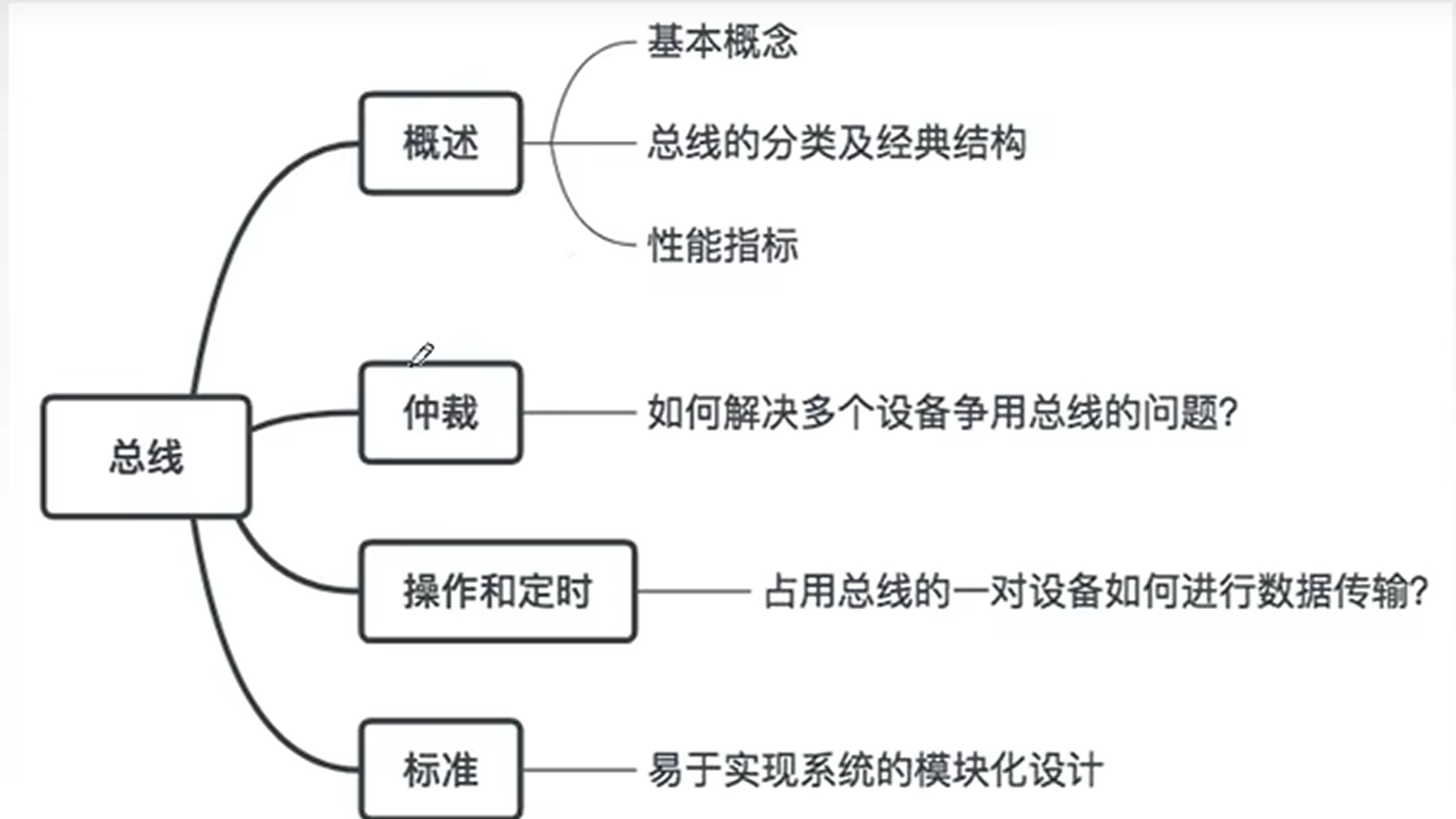
总线的概念:
总线是连接多个部件的信息传输线,是各种不见共享的传输介质,其由许多传输线或通道构成,每条线可以擦混送一个二进制位。
特点:
- 总线上有超过一个信息接收部件
- 任一时刻,只允许与一个部件向总监发送信息
总线的分类:
按照总线功能分类:
片内总线:芯片内部的总线
他是CPU芯片内部寄存器和寄存器之间、寄存器和ALU之间的公共连接线
例如处理器和Cache之间的总线
系统总线(板级总线)
1.数据总线DB
双线传输 (双向)
位数即为数据总线宽度,即机器位数,与储存器字长相关
2.地址总线AB
单向总线,总是又CPU发出地址指向存储器
表示主存或I/O设备上 存储单元的位置
地址总线的位数与存储单元的个数有关,与存储单元的二进制位长度无关 -> 即存东西的地方的大小和地址大小无关,32位地址可以指向8位数据类型
地址总线 n 条可以寻址到 2 ^ n 个地质单元
3.控制总线CB
发出各种控制信号,单一控制通常单向,控制总线总体双向
用于复位、时钟、中断相关,总线请求、存储器读写等
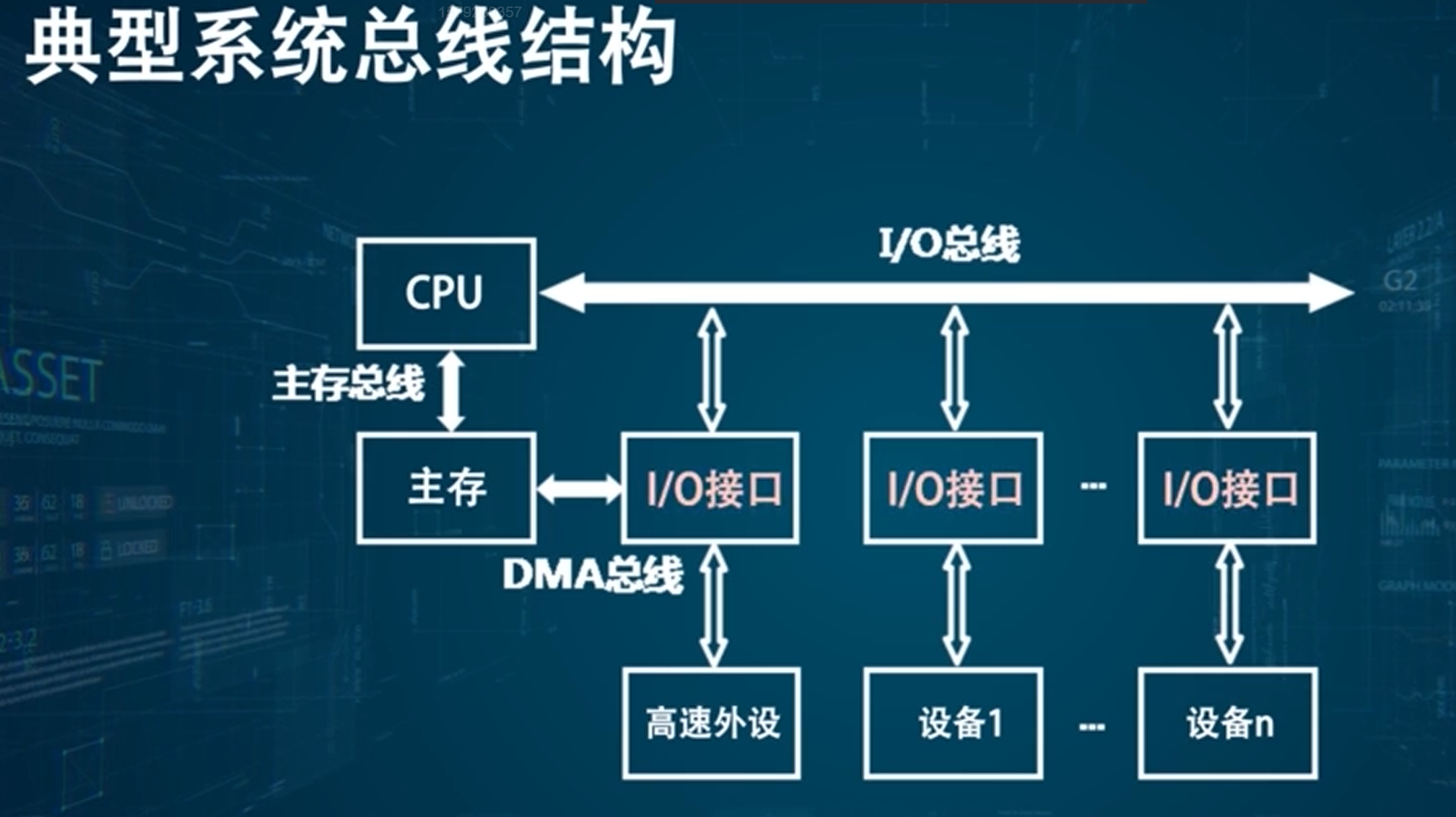
CPU平时就是不断从主存中去取指令,然后执行指令,不断反复
主存总线:具有三总线的结构
DMA:直接存储器访问,在DMA控制器的控制下进行工作的
通信总线:
计算机系统之间,或者计算机与其他设备之间的信息传输线,包括串行和并行两种工作模式
特点:
- 类别复杂,连接规格、传输距离、速度、工作模式各不相同
- 传输速度和距离成反比
各个总线的结构:
对应总线标准举例,看起来不太重要
常见的系统总线:
- ISA:Industry Standard Architecture,工业标准体系结构。
- VESA:Video Electronics Standards Association,视频电子标准协会。
- PCI:Peripheral Component Interconnect,外围设备互连。
- PCI-E:PCI Express,外围设备互连扩展。
常见的 IO 总线:
- IDE:Integrated Drive Electronics,集成驱动器电子技术。
- SCSI:Small Computer System Interface,小型计算机系统接口。
- USB:Universal Serial Bus,通用串行总线。
- IEEE-1394:FireWire,高速串行总线。
常见的通信总线:
- RS-232C:Recommended Standard 232C,推荐标准 232C,串行通信总线。
- IEEE-484:通用仪器总线,并行通信总线。
按照数据传输格式分类:
串行,并行:
串行通信:
在单条一位宽的传输线一位位传输
适宜远距离数据传输,成本低
一个字节分八次传递
例如USB
并行通信:
- 在多条一位宽的传输线并行传输
- 适宜近距离的数据传输,通常 < 30m
- 短距离低时钟频率下传输速度原快于串行
总线的各种结构:
(详见saurlax)
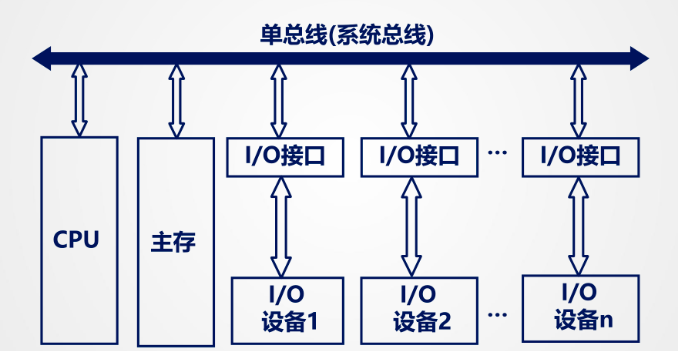
单总线结构:CPU 与主存、I/O 设备之间通过同一总线进行数据传输,这样可以提高 CPU 的效率,但是会降低总线的传输速率。
结构简单,成本低,易于接入新的设备
缺点:带宽低,负载重,不支持并发
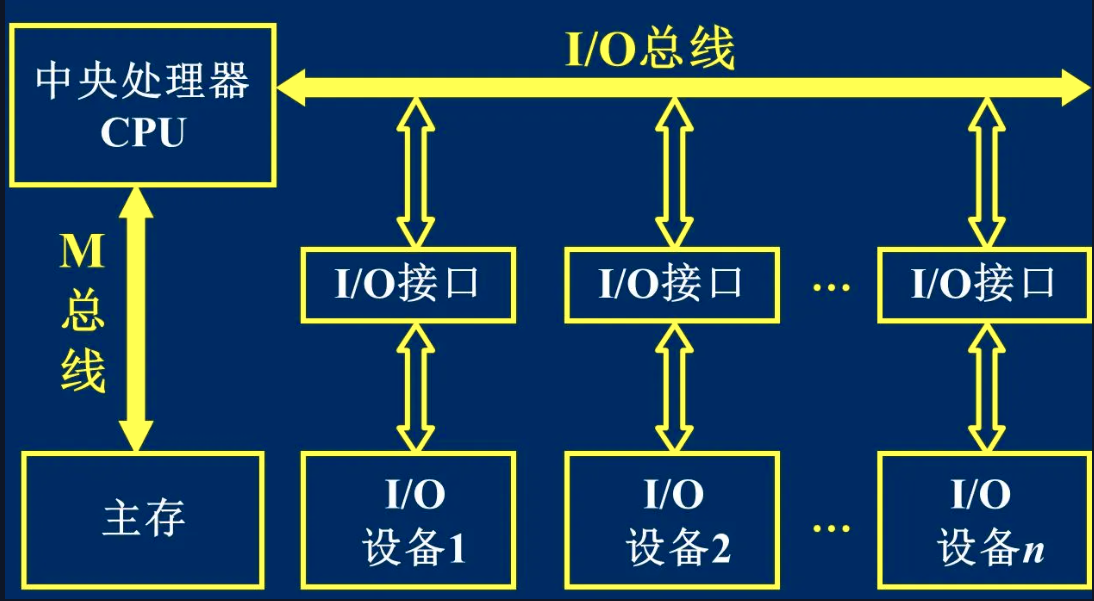
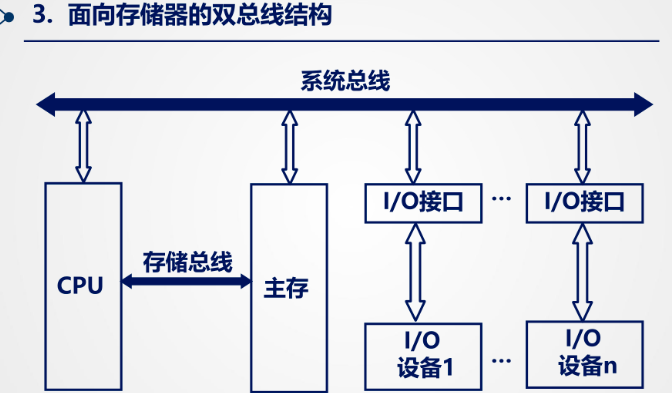
面向 CPU 的双总线结构:其中 M 总线为存储总线,各 I/O 设备通过 I/O 总线与 CPU 通信。但是 I/O 设备与主存之间的数据传输需要通过 CPU,这样会降低 CPU 的效率。
以存储器为中心的双总线结构:在单总线结构的基础上增加一条 CPU 与主存之间的总线,这样提高了传输速度,坚强了系统总线负担,保留了主存与I/O直接交换信息的特点
三总线结构:任意时刻只有一条总线处于工作状态,主存总线和 DMA 总线不能同时读取主存,当 CPU 执行 I/O 指令时才会使用 I/O 总线。
提高IO设备性能,使其更快地相应命令,提高系统吞吐量
缺点:系统工作效率较低
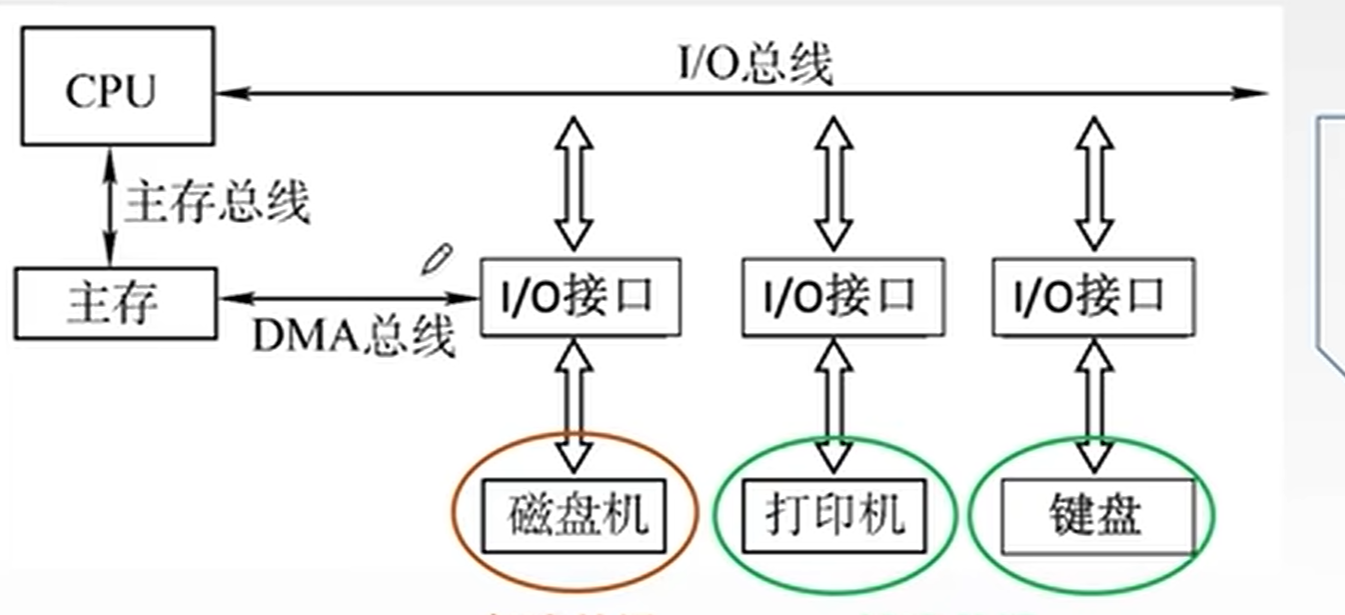
另一种三总线结构:CPU 和 Cache 以及一些局部设备通过局部总线连接,Cache 可直接通过系统总线访问主存,其他设备通过拓展总线和拓展总线接口与系统总线连接。
四总线结构:增加一条高速总线与高速设备相连,拓展设备通过拓展总线结构接入高速总线,可以让高速设备与 CPU 的联系更加密切。
按照时序控制方式:
同步总线、异步总线
总线的特性
貌似并不重要
机械特性
物理尺寸、插头形状、管脚数、排列顺序
电气特性
信号线的电平范围。逻辑“1”、“0”、TTL电平、CMOS电平等
功能特性
没根传输线的功能:数据、地址、控制
时间特性:
信号的前后时序关系
主存部分在后面
总线的性能指标
- 总线位宽:数据总线的位数,也就是数据线的根数。
- 总线带宽:数据总线的最高传输速率,通常以 MB/s 为单位。
- 传输速率:实际的数据传输速度。MT/s 和 GT/s ->百万次传输/秒 和 十亿次传输/秒
- 时钟同步:总线的时钟信号同步/异步。
- 总线复用:是否将地址线与数据线复用,从而减少空间和成本。
- 信号线数:地址线、数据线、控制线的总数。
- 控制方式:总线的控制方式,如并发、自动、仲裁、逻辑、计数等。
- 其他:带载能力、电源电压等
总线的判优逻辑
总线事务和控制:
总线控制:
解决有多个设备/部件时,如何避免多个部件同时发生信息(否则会冲突),如何决定何时由哪个部件发送信息,以及防止信息丢失,由总线控制器统一管理
典型信号类型:
总线事务:
总线事务、主设备、从设备:

总线判优(总线仲裁):

分布式:
特点:不需要中央仲裁器,每个潜在的主模块都有自己的仲裁其和仲裁号,多个仲裁器竞争使用总线
过程:

人话:把判由算法分布至仲裁号,用仲裁号的比较代替控制部件的算法,从而取代中央仲裁器
集中式:
流程:
- 主设备发出请求信号
- 若多个主设备同时要求使用总线,则由总线控制器的判由、仲裁逻辑按一定的优先等级顺序缺点哪个主设备能使用总线
- 获得总线使用权的主设备开始传送数据
当设备发出 BR 信号后,总线控制部件发出 BG 信号,从离 CPU 最近的设备开始逐渐传递,知道到达的接口有总线请求便停止传递 BG 信号,此时该设备获得总线使用权并发出 BS 信号表示占用总线。
控制线数:3
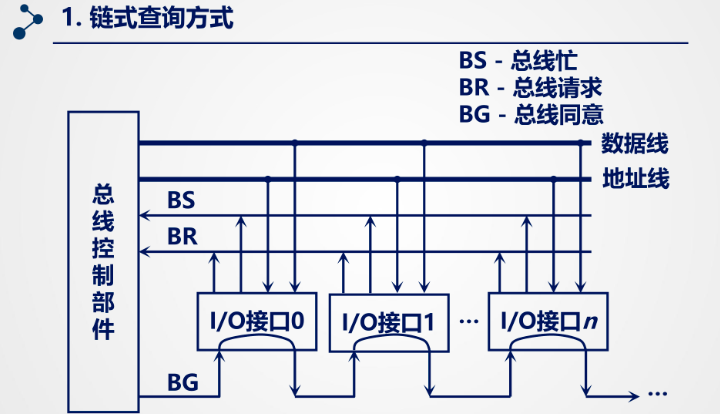
BS、BR、BG都是控制总线的范畴
优点:易于拓展设备
缺点:1. 对电路故障敏感(中间的接口故障,后面的接口收不到BG信号)
2. 优先级低的设备很难获得允许
总线收到 BR 信号后,当 BS=0 未被使用时,总线计数器发出设备地址信号,与地址匹配的设备获得总线使用权,并发出 BS 信号结束计数器。计时器通过设备地址线广播正在寻找的设备地址。
控制线数 log2n向上取整 + 2 = 总线请求(1) + 总线忙(1) + 总线允许 (log2n上取整)
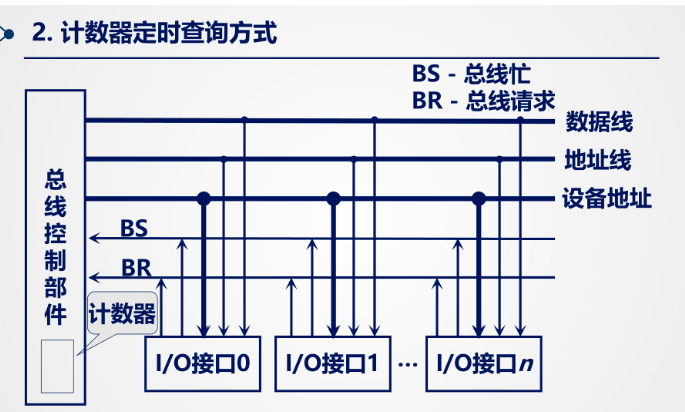
优点:某个接口发生故障对其他接口使用不敏感,
缺点是新增了设备地址,让控制变复杂,
3.独立请求方式:
每个设备均有一对总线请求线 BR_i 和总线同意线 BG_i。总线内有排队电路,可以根据设定的优先次序决定响应的设备。
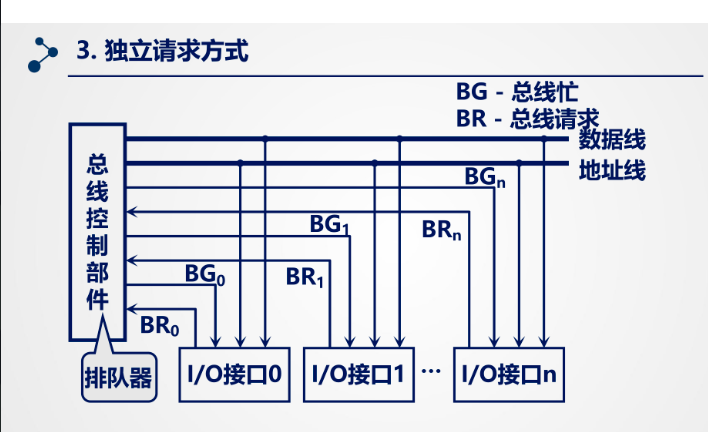
注意:无BS和设备地址线
主要部件:排队器,同时使用则排队,选择优先权高的(通过算法选择)。
优点:响应速度快,优先次序控制灵活。
缺点:但是控制线数目多,总线控制逻辑更加复杂
总线的通信控制
总线通信控制是为了解决通信双方协调配合的问题。
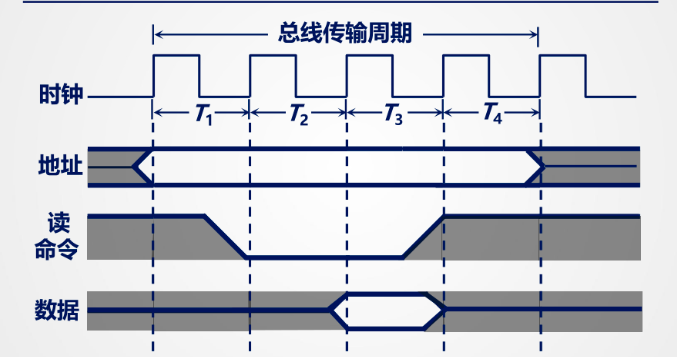
传输周期
总线传输周期分为四个阶段:
- 申请阶段(T1):主模块申请,总线仲裁决定。
- 寻址阶段(T2):主模块发出地址和命令。
- 传数阶段(T3):主模块和从模块蒋欢数据。
- 结束阶段(T4):主模块撤销相关信号。
通信控制方式
分为四种通信方式:同步、异步、半同步、分离式
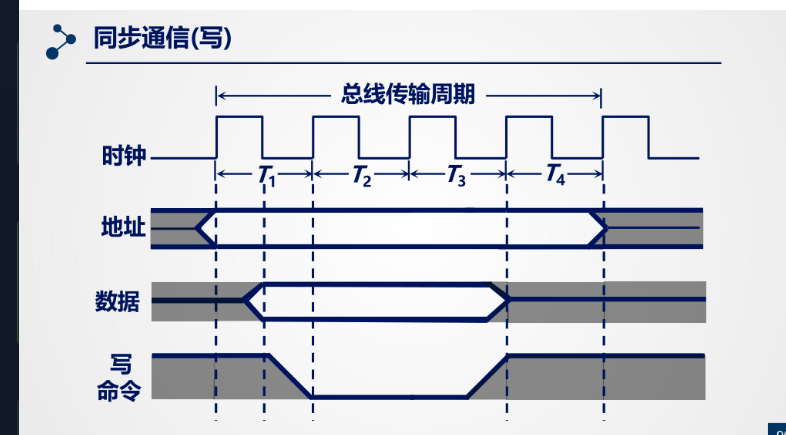
同步通信
发送时钟信号来同步数据传送
读:
写:
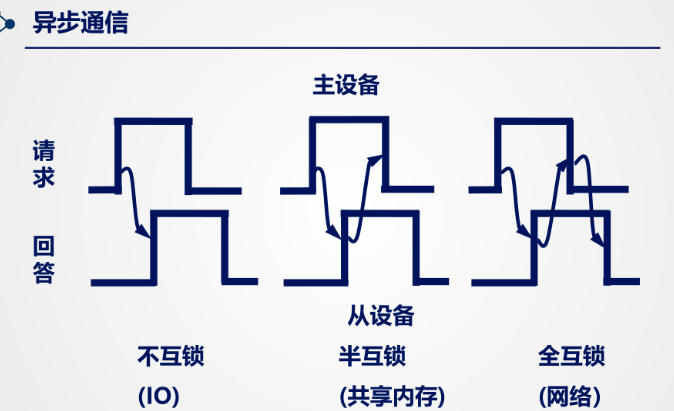
※异步通信:
其分为三种:不互锁,半互锁,全互锁(以下为Saurlax原文)
- 不互锁方式:主模块发出请求信号后,不等待从模块的应答信号,而是等待一段时间后确认从模块收到信号后撤销请求信号。
- 半互锁方式:主模块发出请求信号后,等待从模块的应答信号,从模块收到请求信号后发出应答信号,主模块收到应答信号后撤销请求信号。
- 全互锁方式:主模块发出请求信号后,等待从模块的应答信号,从模块收到请求信号后发出应答信号,主模块收到应答信号后撤销请求信号,从模块收到撤销信号后撤销应答信号。
- 波特率:单位时间内传输的二进制数据的位数。 比特率:单位时间内传输的二进制有效数据的位数。 此事在计网中亦有记载
半同步通信:
结合了同步通信和异步通信优点
发送方依然发送时钟(用系统时钟前沿触发),而接收方根据自身情况返回消息给发送方,使发送方进行相应的调制,对于不同设备的模块,增加一条等待(wait)相应信号线
//TODO
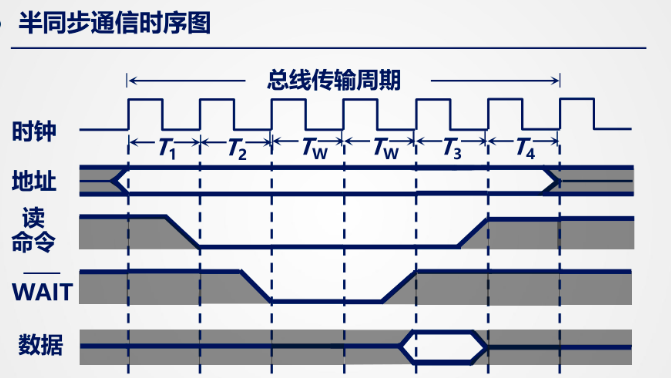
分离式通信:
上面三种方式在从模块准备数据的时候总线是空闲的,所以可以使用分离式通信进一步提高总线的利用率。分离式通信将一个总线传输周期分为两个子周期,在子周期 1 时,主模块申请占用总线,将命令和地址发送后立即释放总线,从模块在子周期 2 时将数据发送给主模块。

三、存储器
概述
分类
按存储介质:
- 半导体存储器:TTL(双极型半导体存储器)、MOS,易失性存储器。 特点:体积小,功耗低、存取时间短、易失性
- 磁表面存储器:磁头在载磁体上做读写操作,例如磁带、磁盘、磁鼓,非易失性存储器。
- 磁芯存储器:硬磁材料制成的环状元件,非易失性存储器。
- 光盘存储器:利用激光技术在磁光材料上进行读写操作,非易失性存储器。
按数据保存方式:
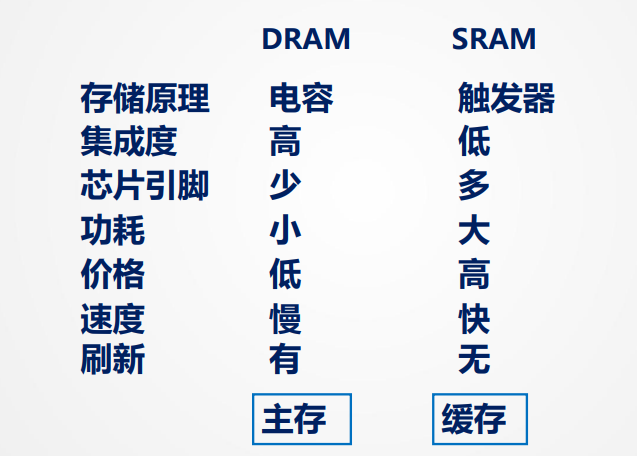
随机存储器(RAM):存取时间与地址无关,断电后数据丢失(易失性)。
- 静态 RAM(SRAM):触发器原理,存取速度快,价格高,主要用于缓存。
- 动态 RAM(DRAM):电容原理,存取速度慢,价格低,主要用于主存。
只读存储器(ROM):只读,断电后数据不丢失(非易失性)。
- PROM:可编程只读存储器,通过熔丝方式编程,只能一次性编程。
- EPROM:可擦除可编程只读存储器,通过紫外线擦除。
- EEPROM:电可擦除可编程只读存储器。
- Flash Memory:闪存,具有 EEPROM 的特点,但是擦写速度更快。
按数据存取方式:
- 直接访问:访问时间不随访问位置而变化,内存使用
- 串行访问:访问时间随访问位置变化,如磁带
- 部分串行:介于上述二者之间,磁盘使用(寻道直接,等待串行)
按作用分类:
- 主存储器:可以直接和 CPU 交换信息。(主存 = 内存 ->掉电丢失)
- RAM:静态 RAM、动态 RAM。
- ROM:PROM、EPROM、EEPROM。
- 辅助存储器:磁盘、磁带、光盘等,用于长期存储数据。
- Cache Memory:高速缓冲存储器,存放 CPU 频繁访问的数据和指令。
- Flash Memory:闪存
注:寄存器是在CPU内部的,通过寄存器名直接访问,存储器主要是指内存
层次结构
结构图:
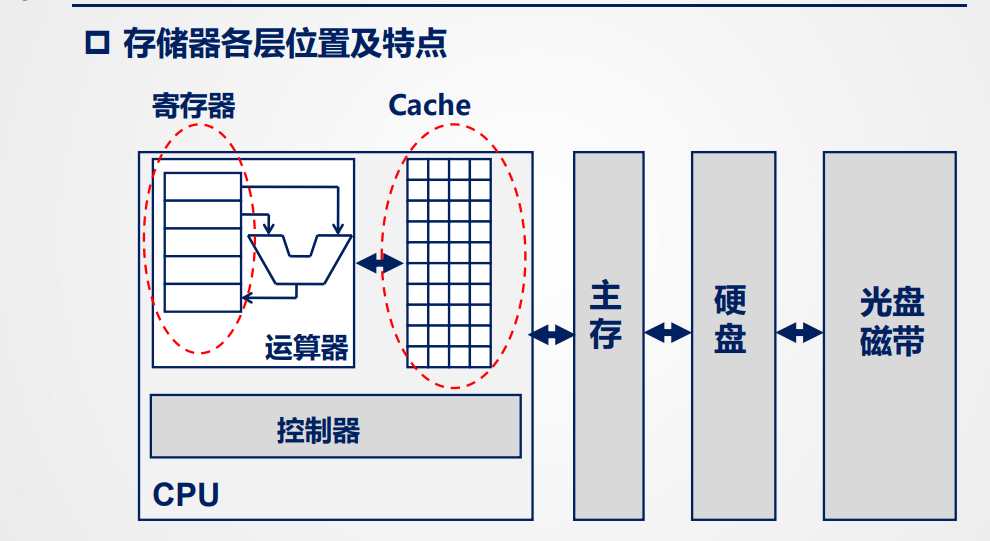
层次图
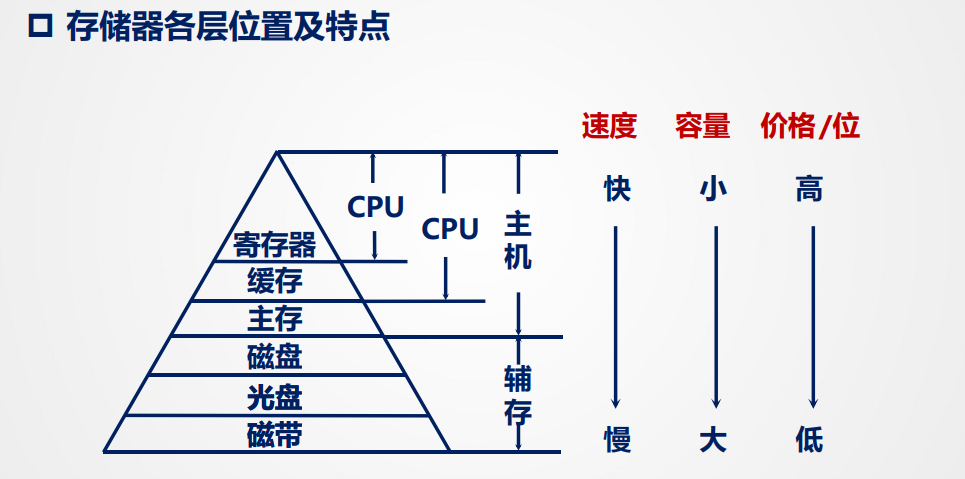
可以看到层次图可以被分为两个主要层次:缓存和主存
- 缓存 - 主存:解决速度匹配和成本问题
- 主存 - 辅存:主要解决速度、容量、成本问题
主存地址
通常计算机可按字节寻址,也可以按字寻址
字节序问题:
处理多字节数据再内存中的存放顺序
大端:
数据的低位存储在内存地址的高位: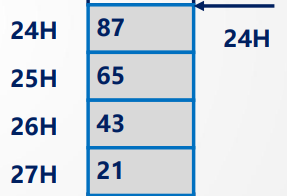
如:0x87654321
87(数据位高位)放在地址的低位,21(低位)放在地址的高位
小端:
与大端相反
数据的低位存储在内存地址的低位: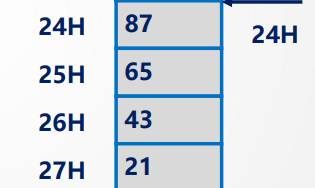
主存的技术指标
存储容量:
主存能存放的 二进制数的总位数
公式:存储器容量 = 存储单元个数 * 存储字长
访存周期:
相邻两次存储器访问的时间间隔
存储器带宽
单位时间内存储器存取的信息量(B/s,位/s、字/s)
芯片的译码驱动
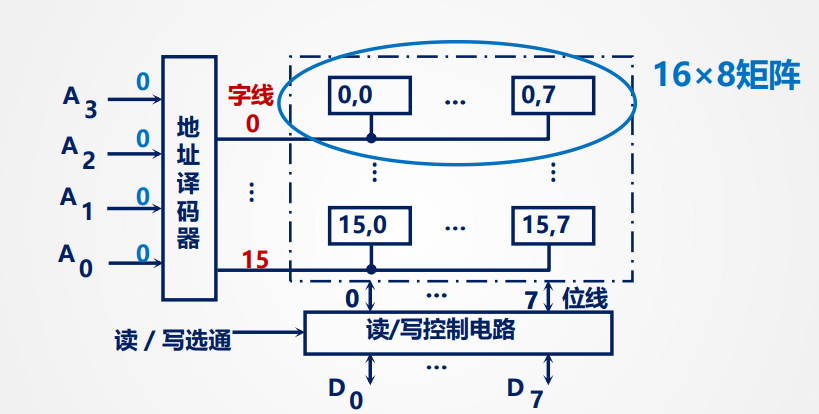
线选法
用一根 字选择线 直接选中存储单元,例如一个字节
16 * 8矩阵 :16条字线 一个存储单元为8个b
重合法
两个方向的交叉点为选中单元,仅需约 2*log₂N 根地址线,显著节省引脚
1024 * 1 矩阵
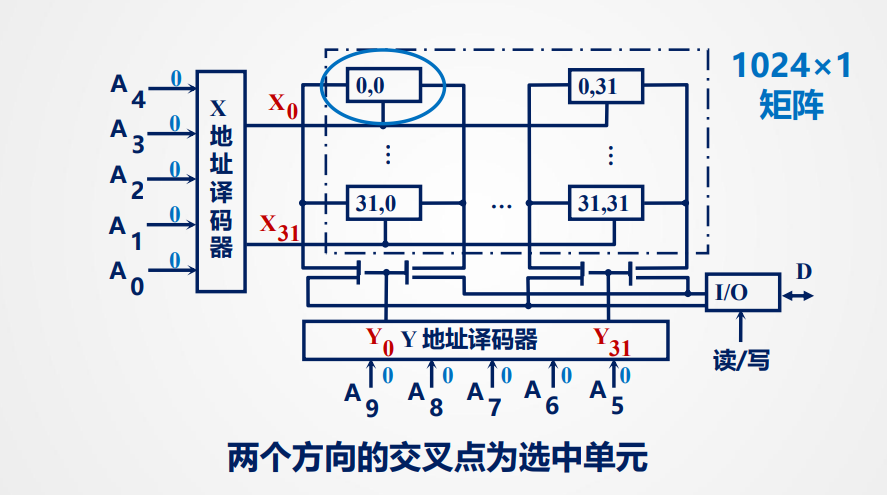
1024 为可选单元 ,1为存储单元所含二进制位(b)
随机存储器
静态RAM(静态随机存储器):主要用于缓存
动态RAM(动态随机存储器):主要用于内存
动态RAM(DRAM)的刷新问题
由于电容的漏电,需要定时刷新电容的电荷。
集中刷新
一段时间内集中刷新所有存储单元。在刷新期间不能进行读写操作。
分散刷新
在每个存取周期中刷新一行存储单元。刷新时间分散,但存取周期变长了。
异步刷新
充分利用最大刷新周期,例如最大刷新周期为 2ms,存储芯片为 128×128,则可以每隔 2ms÷128=15.625μs 刷新一行。如果将刷新时间安排在 CPU 译码阶段,则可以完全不影响读写操作。
SRAM和DRAM的比较:
※存储器的扩展方式
扩展分为:
1.字扩展 2.位扩展 3.字、位扩展
- 字扩展:增加存储字的数量(容量)
- 位扩展:增加存储字长(位数增大)
- 字位扩展:都增
与CPU的连接:
数据线:位扩展
地址线:注意高位地位
还需注意读写控制和存储芯片的片选
※连接样例:
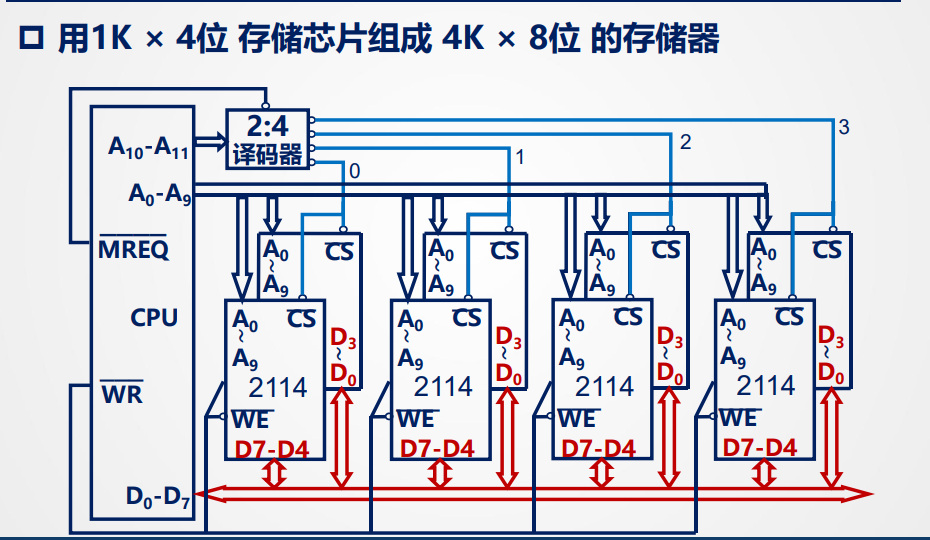
- MREQ:内存请求信号Memory Request,低电平有效,告诉系统AB上的是一个有效内存地址
- WR:低电平时W有效,CPU将要指示地址处写入数据
- WE:写使能,告知芯片具体执行什么,低电平写操作,高电平读操作
- CS:片选,约等于芯片的使能端,代表低电平时开始相应指令
读写电路直接连接数据总线,数据总线是数据传输的通道
连接时:
※注意:当需要接线的时候低位地址线应当一样多
即RAM 芯片和 ROM 芯片所需要的片内地址线根数(地址引脚数)相等且这些芯片的地址引脚可以直接并联接到 CPU 的同一组低位地址总线上。从而连线简单,译码清晰,能大大简化逻辑。
否则,例如ROM字扩展,不仅需要译码来控制使能端,还需要再这上面接入RAM的译码以保证地址再RAM的范围内时不影响ROM,导致逻辑复杂化。
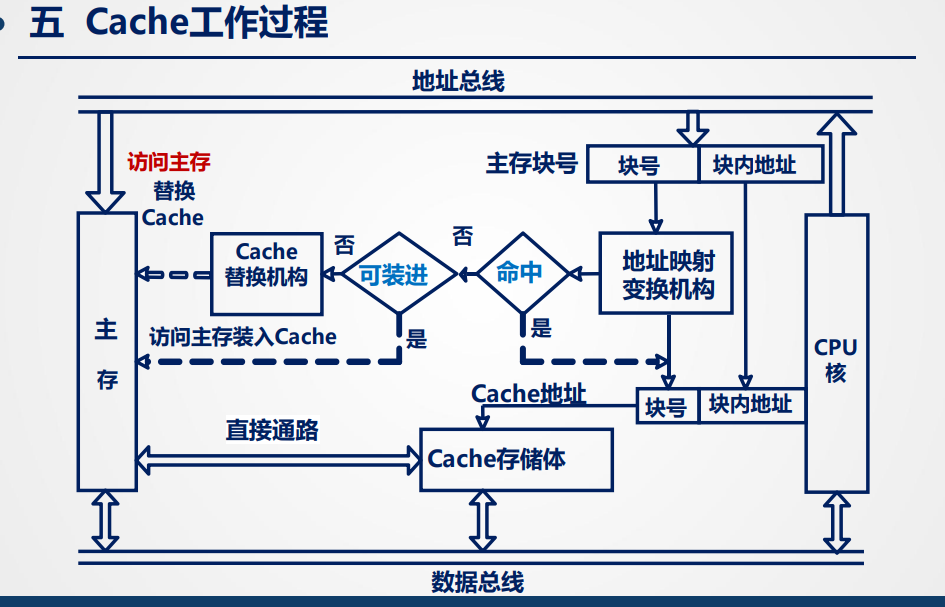
※Cache
前情提要:
Cache提出和解决的问题:
- CPU和存储器速度差异的矛盾
- 解决CPU访存优先级低于I/O的问题
理论基础:局部性原理
- 空间局部性
- 时间局部性
Cache基础
Cache 容量 :
指的是 Cache 能够存储的总数据量大小,通常以字节(Byte)、KB、MB 为单位。
它不包括用于管理 Cache 的标签位(tag)和有效位等额外开销,仅仅是指数据存储部分的总大小。
Cache块长 :
指的是 Cache 与主存之间交换数据的一块连续内存的最小单位。太大可能会载入大量不需要的数据,太小可能无法利用空间局限性
主存与Cache
主存和Cache的块内地址的字数相同,主存块数大于缓存块数
主存地址: 主存块号+块内地址 Cache:缓存块号 + 块内地址
注意:Tag、有效位、脏位、LRU 位 等元数据并不占用可用字长
命中率:
命中:如果主存快已调入缓存,主存块与缓存块建立了对应关系,用标记(Tag)表示
未命中:主存块未调入缓存;主存块与缓存块未建立对应的关系
命中率和Cache的容量和块长有关,等于 -> 命中次数 /总访问次数

所需访问时间为:
$$ T_总 = T_C * P_中 + T_内 * (1 - P_中) $$注:关于同时访问内存和Cache:
在理论上是可行的,但在实际处理器设计中几乎不会被采用,主要是因为内存访问无法被“优雅地取消”,甚至可能因为异常取消导致更长的延迟。因此,提前终止内存访问并不能节省多少时间。
但是公式和学校规定是并发进行的,那就按并发进行来计算吧
效率
效率 e 和命中率有关,平均访存时间如上

关于Cache替换算法
- FIFO算法
- 最近最少使用算法
- 随机算法
Cache与主存的一致性问题
对于同一个内存地址的数据,Cache 中的副本和主存中的副本保持相同(或最终相同)的关系。
虽然 CPU 自己始终从 Cache 读到正确值,但系统中不止 CPU 会访问主存。其他设备(如 DMA 控制器、GPU、网络卡)可能直接读写主存,所以需要处理此一致性问题。
一般有写直达法和写回法两种方法

Cache一致性问题(不重要,但是查AI发现这两个有区别所以拿出来讲一下)
指多喝处理器中每个都有自己私有的Cache,当对同一地址进行读写时可能保存了不同版本,导致了数据出错,违反共享内存的预期。
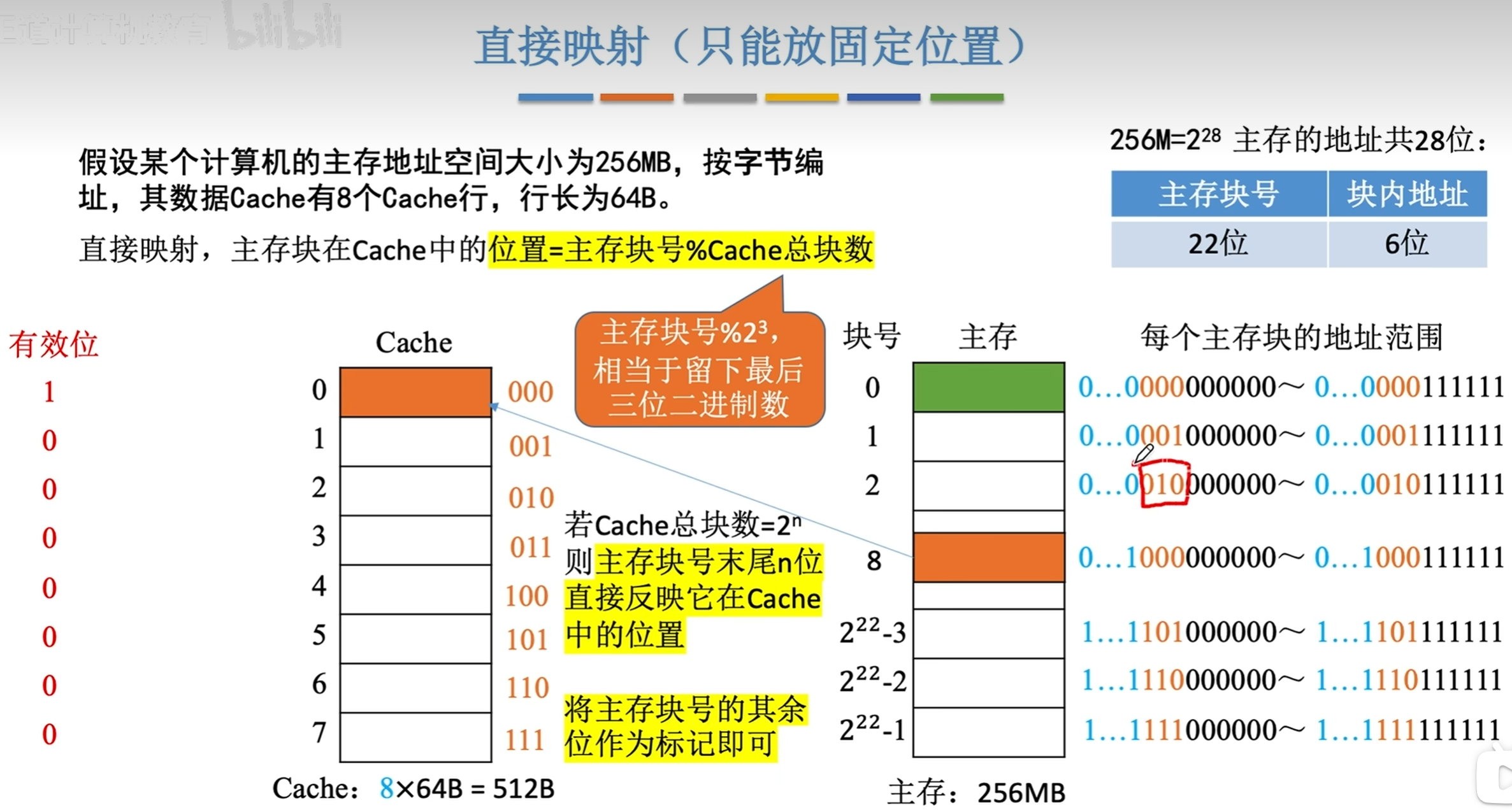
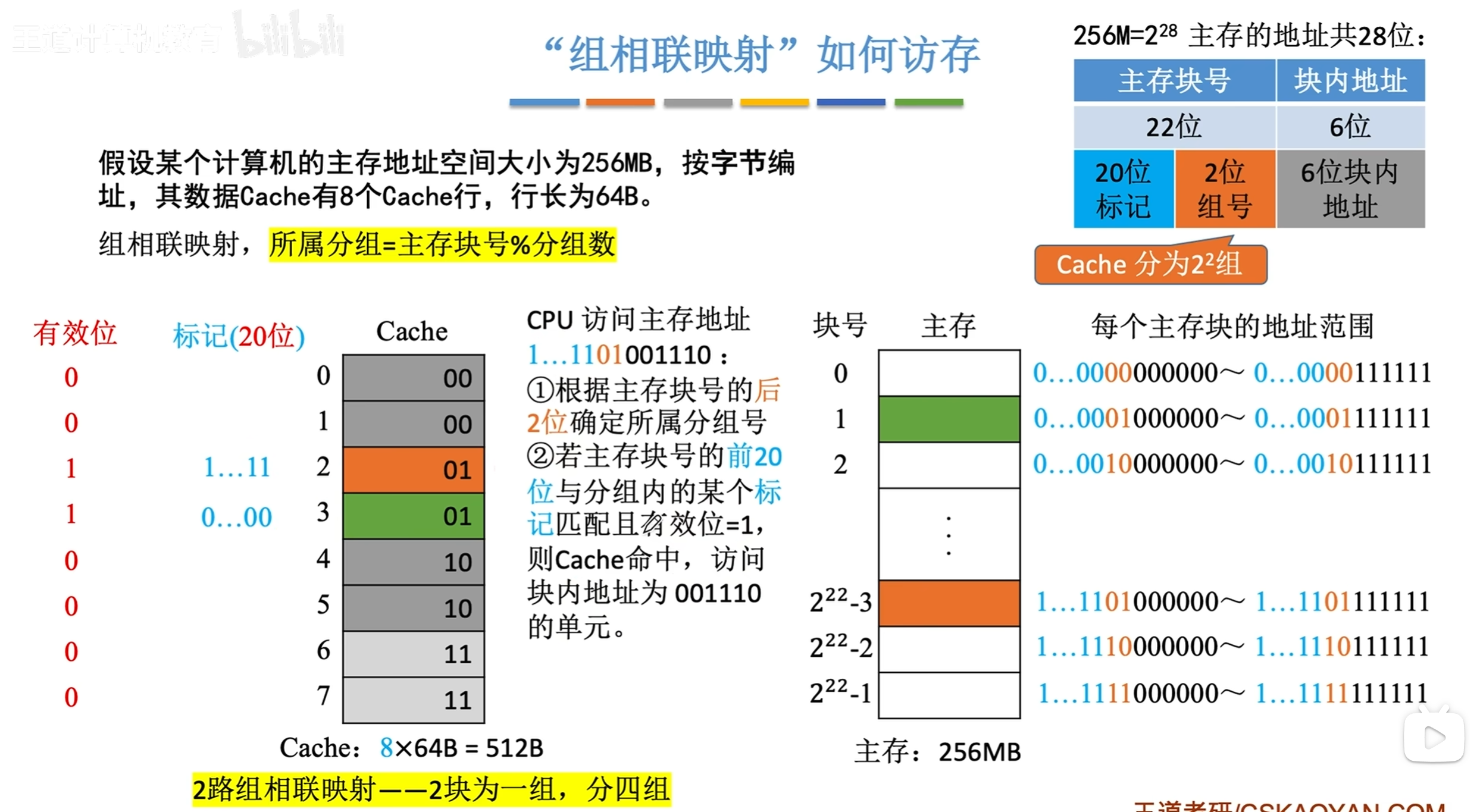
※Cache的映射方式
- 直接映像:每个缓存块 i 可以和若干个主存块 j对应,i = j mod C,其中 C 为 Cache 块数。但每个主存块 j 只会和一个缓存块 i 对应。
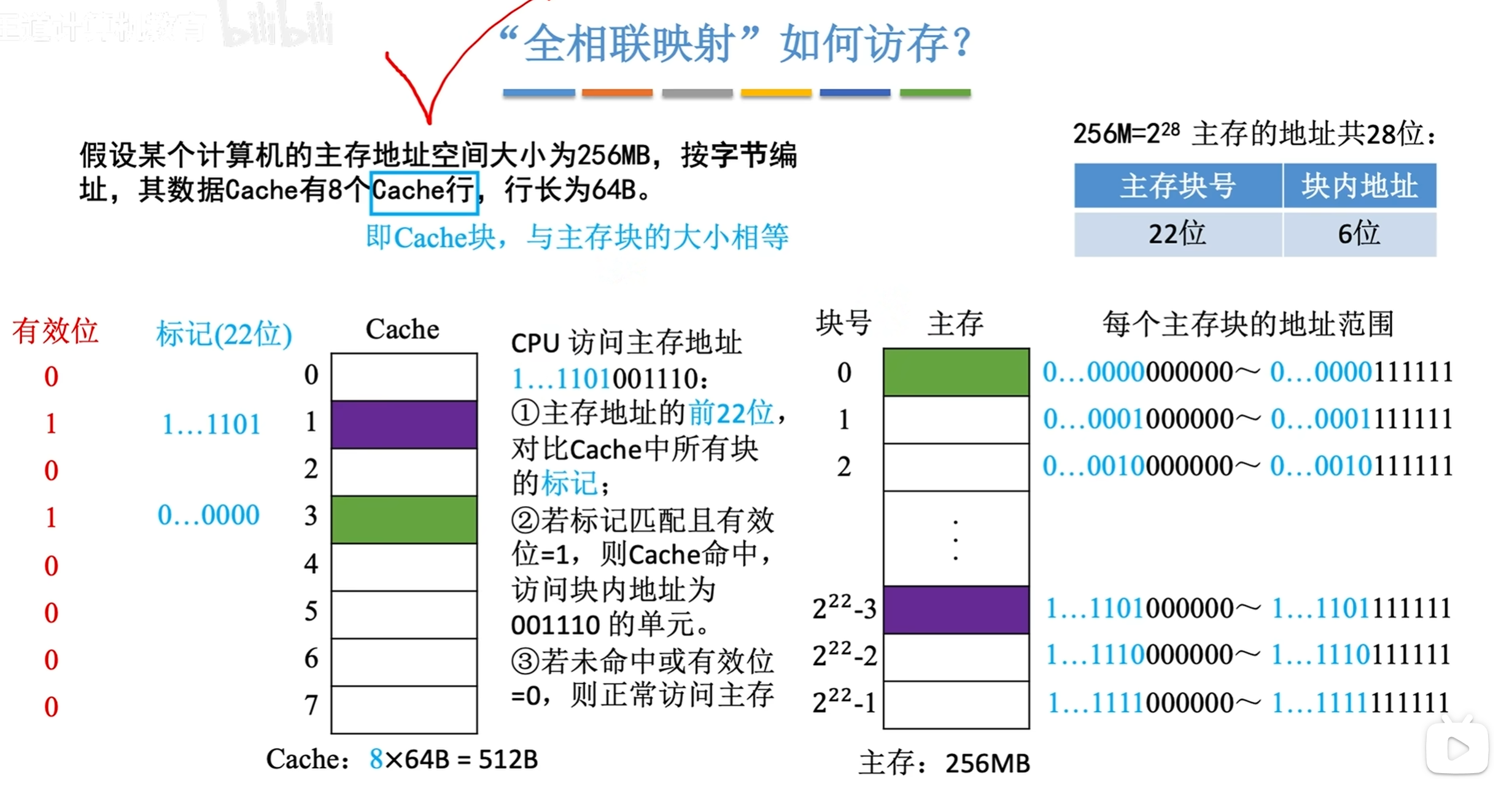
- 全相联映像:主存的任一块可以映射到缓存的任一块。
- 组相联映像:主存的任一块只能映射到缓存的某一组。
关于映射:
内存的地址固定(设主存的地址位为 n),分块之后字块内地址有 b 位(即存2 ^ b 个地址),剩下的 n - b = m位由映像方式决定怎么分,Cache的映射确认是否正确的方式就是Cache的 Tag 位通过某种方式与剩下的位比较。(所需内存地址与所有 Tag 按某种方式比较)
关于Tag位:前面有说,Tag、有效位、脏位、LRU 位 等元数据并不占用可用字长。
即Cache 容量指的是 Cache 能够存储的总数据量大小,不包括用于管理 Cache 的标签位(tag)和有效位等额外开销,仅仅是指数据存储部分的总大小。
Cache块和主存块是一对多的关系
要与标记(Tag)匹配且有效位 = 1才算Cache命中
直接映像
缓存块 i 对应多个主存块 ,i = j mod C,其中 C 为 Cache 块数。 j 为 主存块地址
此时剩下的主存地址 m 被分为 主存标记块号 (t 位 )和区内块号(c 位),Tag位为t位
区内块号决定了内存块在Cache中的唯一位置
查找时,只需根据内存前 t 位查找对应 Tag (因为每个Cache块的后三位相同),若有则成功查找
全相联映射
随意放,此时Tag位为 m = t + c 位,即查找时直接将主存块所属的地址进行比对

剩下的主存地址 m 全部是主存区块标记位
组相联映射
N路组相联映射 -> 每组有N个块,主存的任一块只能映射到缓存的某一组。
所属分组 = 主存块号地址 % 分组数 ( 类似直接映射 )
设每组内2 ^ r 块,则有
主存字块标记 s = t + r 位,即Tag 有 s 位
组地址有 q = c - r 位,即组内有2 ^ r 个块
此时只需要对照 q 位 Tag 位 且每组可以有多个块号

当一个块一组 -> 直接映射 当全部块一组 -> 全相联映射
三种方式比较:

注:二维变量大部分是行优先存储,MATLAB、R为列优先存储
并行存储结构
双口RAM
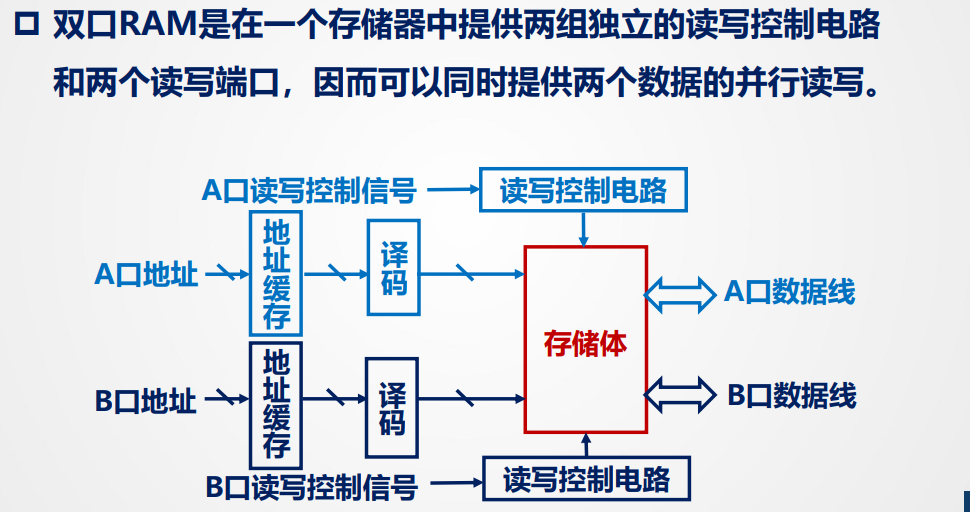
用途:
- 通用寄存器组
- 指令预取部件
- CPU和其他处理器的连接部分
多模块存储器
单体多字
一次存取周期取出多个子后逐次送至CPU核内执行,适用于指令数据在内存中连续存放的情况
缺点:取指冲突、读操作数冲突、写数据冲突(凑够字才能写)
多体并行
存储器由多个存储体构成,各存储体有相同的容量和存取速度,每个存储体有独立的:地址寄存器、数据寄存器、地址译码等,可以独立工作
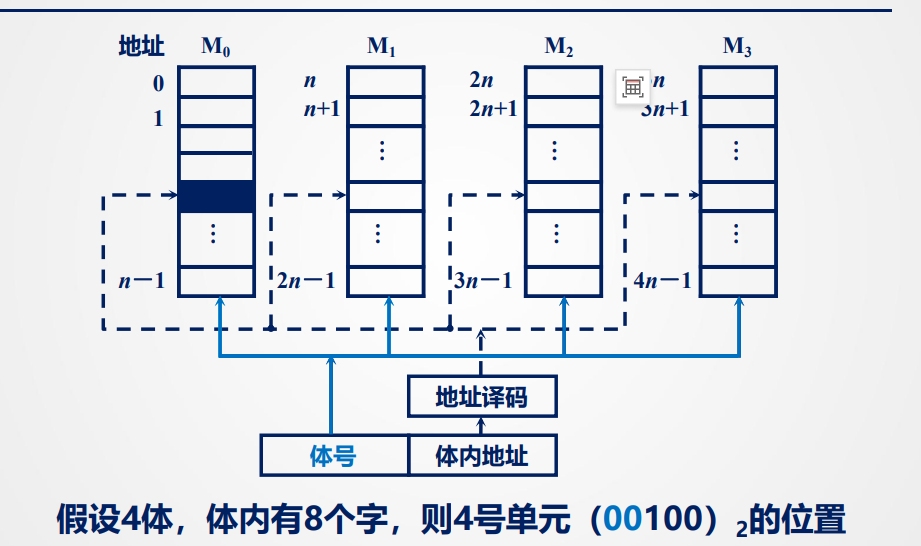
特点:
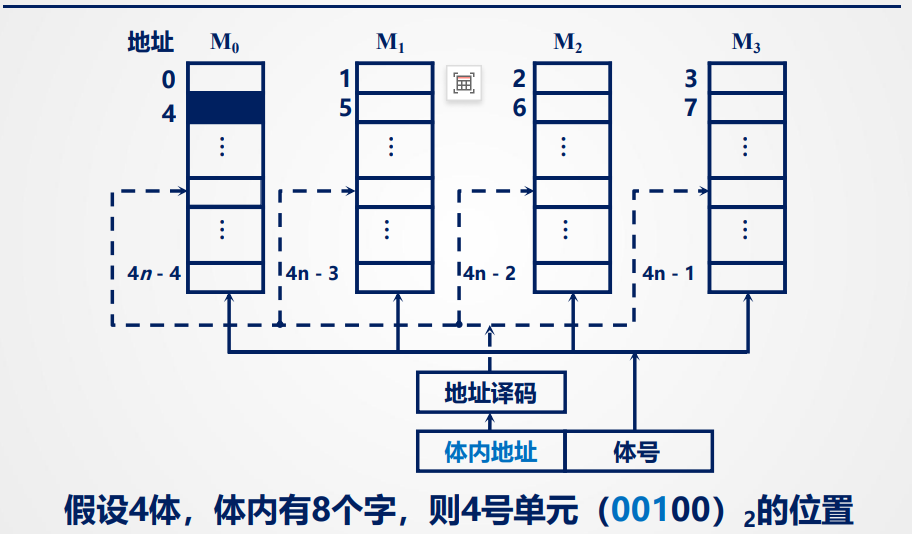
在不改变存取周期和数据总线宽度的前提下,按照地址连续访问可以增加存储器的带宽(每个都能用上),这样每个时钟周期可以完成一个数据传输。
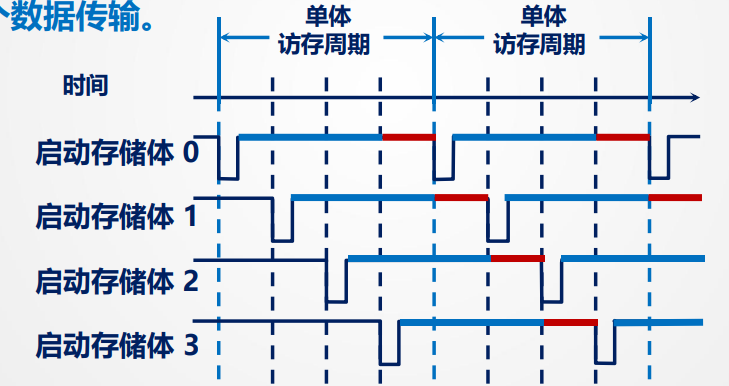
连续读取n个连续地址的存储字的所需时间为:T + (n - 1)t (t为以此传输周期,T = 4 t)
虚拟存储机制
分类:页式、段式、段页式
虚拟内存看OS去
数据校验码:
码距:编码体系中任意两合法编码之间不同的二进制位数的最小值,其决定了编码的纠错和检错能力

数据校验码分为:奇偶校验码、循环冗余校验码、海明码
用于在传输过程中确保信息正确
奇偶校验码:
首位是校验位,填后判断 1 个数的奇偶
循环冗余:
计网 or AI
海明码:
增加的检测位的位数 k :
$$ 2^k ≥ n + k +1 -> (n为原数据位数) $$检测位的位置:
$$ 2^i (i = 0,1,2,3...) $$分组与检错原理:
第 i 组指二进制第 i 位为1的为一组,对每个组进行奇偶校验,则出错时出错的组表示与二进制第 i 位有关,这些位加起来即为出错的地方。
四、输入输出系统
发展阶段:
查询阶段:
在其CPU和外设分散连接,CPU 和 I/O 串行工作踏步等待,机器速度慢
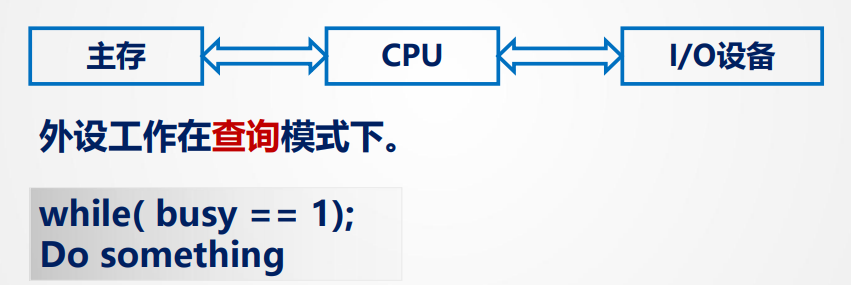
CPU一直询问设备是否完成工作
接口模块和DMA阶段:
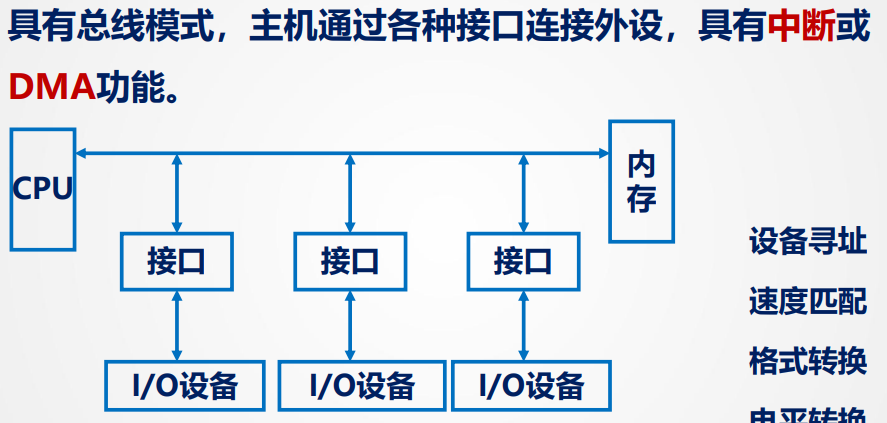
接口又称作I/O控制器
通道结构:
负责管理IO设备以及实现主存和IO设备之间交换信息的部件
其有专门指令,能独立执行由通道指令编写的输入输出程序
但是其还不能完全把CPU解放,CPU还需要进行码制转换之类的工作
外围处理机
又称为I/O处理机,独立于主机工作,除了具备通道功能之外,还具备码制转换、格式处理、数据校验等功能。
分类
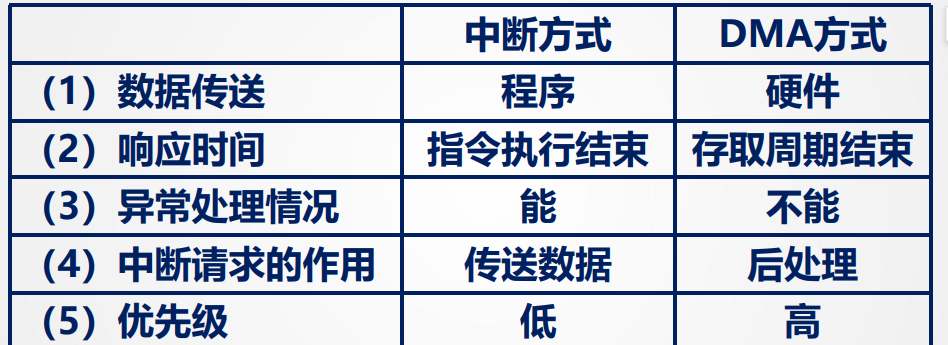
I/O的五种控制方式:
程序查询/轮询方式:
CPU不断查询/轮询 I/O控制器中的状态寄存器,检测到完成再取出
程序中断方式:
等待I/O时CPU先去执行其他程序,I/O完成后向CPU发出中断请求,CPU相应中断请求
缺点:若中断过于频繁,要花大量时间处理中断,CPU利用率严重下降
以上两种数据流: 键盘(或其他外设) -> I/O接口的数据寄存器 -> 数据总线 -> CPU某些寄存器 -> 主存
DMA控制方式:
DMA接口即DMA控制器,也是一种特殊的I/O控制器
主存和IO设备之间有一条直接的数据通路(DMA总线),CPU向DMA接口发出W/R命令,并指明参数(主存地址、磁盘地址、读写数据量等)
DMA控制器(接口)自动控制磁盘和主存的数据读写,每完成一整块数据读写才会向CPU发送一次中断请求
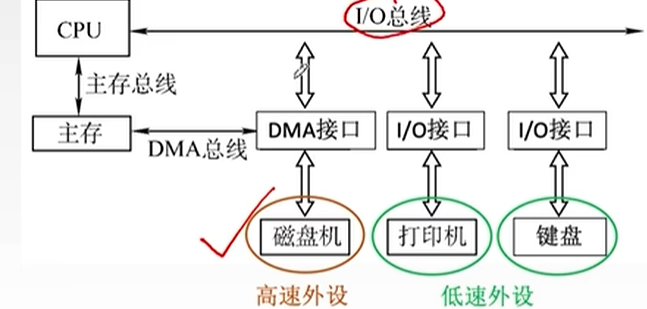
####通道控制方式
“弱化版”CPU,可以识别并执行一系列的“通道指令”,指令种类和功能比较单一
CPU向通道发送I/O指令,指明通道程序在内存中哪个位置,并指明要操作的是哪个IO设备,然后CPU做其他事情,通道执行完规定任务后猜向CPU发中断请求
I/O系统基本组成
I/O 软件
包括驱动程序、用户程序等
- I/O 指令:属于 CPU 指令的一部分,一般格式为:操作码(标志)+命令码(指令功能)+设备码(地址码)。
- 通道指令:对具有通道的 I/O 系统专门设置的指令,用以指出数组的首地址、传送字数、操作命令等。对具有通道的计算机中实际数据传输由通道完成,通道程序提前编制好放在主存中。
I/O 硬件
通道 -> 设备控制器 -> 设备
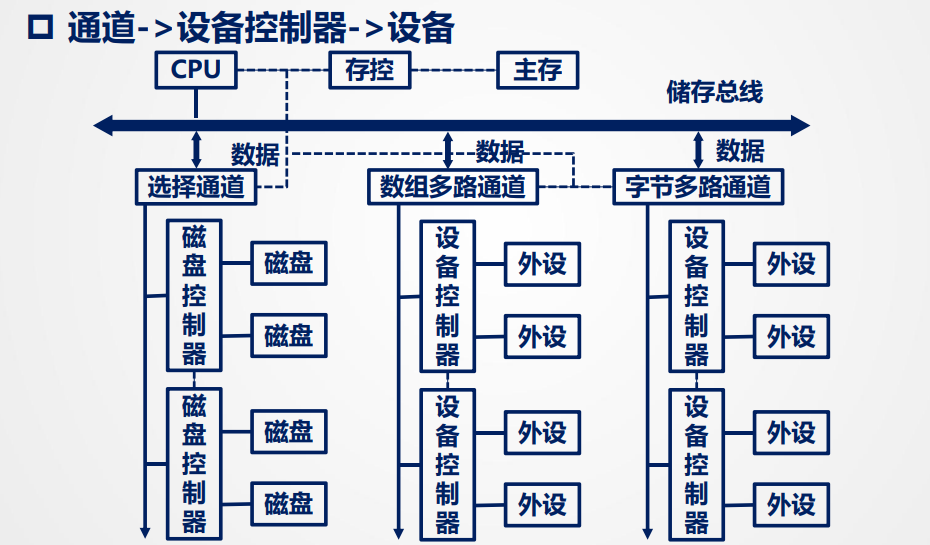
一个通道可以连接多个同类型控制器
一个控制器可以被多个同种设备连接
I/O 设备编址方式:
统一编址:
I/O占用存储器地址空间,无需使用专门的I/O指令,用取数、存数指令访问 I/O 设备。
减少存储器最大容量
不统一编址:
I/O地址和存储器地址分开,用专门的 I/O 指令访问 I/O 设备。
不占用主存容量
同地址怎么分辨? -> 采用不同指令形式来区分访问对象
设备选址:用设备选择电路识别设备是否被选中。
接口类型
数据传送方式:串行或异步。
灵活性:可编程接口(8255、51),不可编程接口(8212)
通用性:通用接口(8255、51)、专用接口(8279、75)
联络方式:
- 立即响应
- 异步工作采用应答信号
- 同步工作采用同步时标
I/O 设备与主机的连接方式:
- 辐射式连接:每台设备都配有一套控制线路和一组信号线,不便于增删设备。
- 总线连接:设备通过总线与主机连接,便于增删设备。
中断接口电路
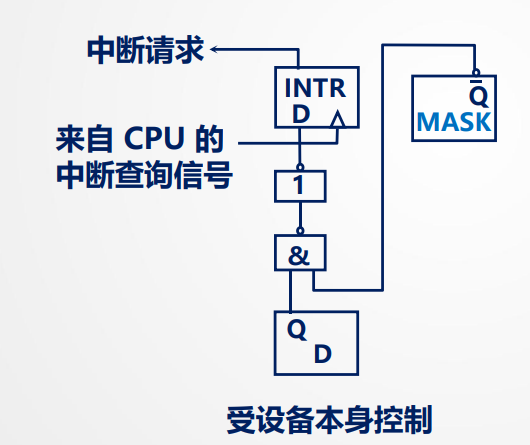
INTR:中断请求触发器 -> INTR = 1 则有中断请求
MASK:中断屏蔽触发器 -> MASK = 1 则被屏蔽
一个请求源对应一个中断屏蔽触发器,多个终端屏蔽触发器组成中断屏蔽寄存器
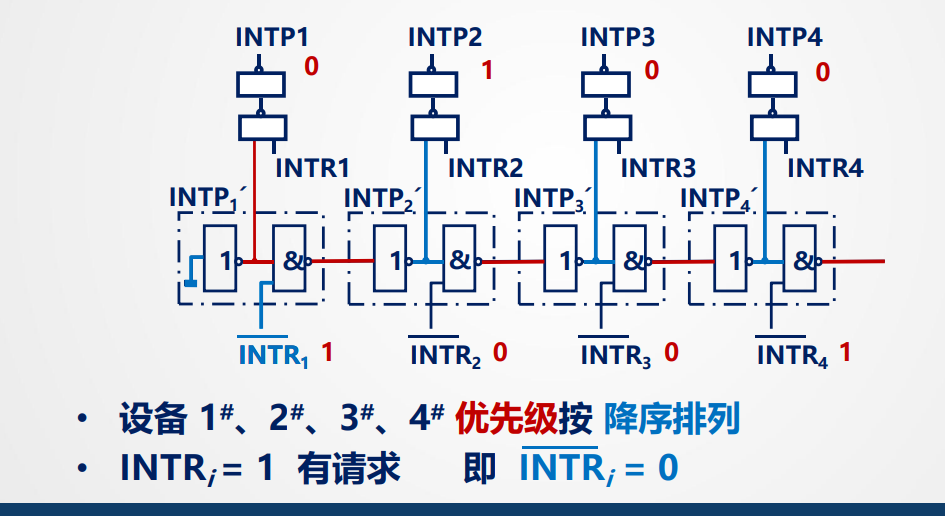
中断判优:
1.硬件排队器
2.软件实现(程序轮询)
向中断服务程序跳转
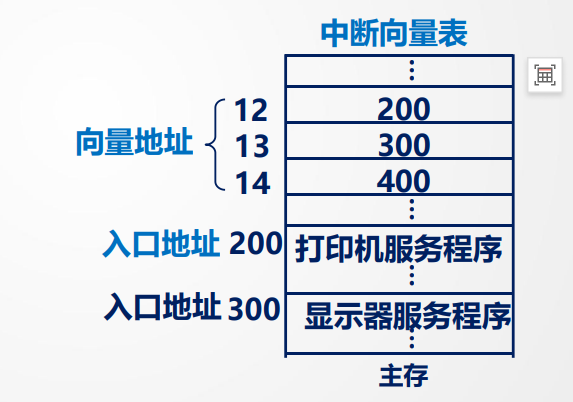
1.由硬件产生向量地址找到入口地址
中断形成部件给出向量地址(中断向量号),然后在中断向量表中找到向量地址所代表的服务程序
2.软件查询法
通过软件转到各服务程序的入口地址
中断处理
中断处理过程
CPU响应中断的条件:
- CPU的中断允许触发器 EINT = 1 (通过开关中断调整)
- 相关的中断掩码(MASK) = 0
- 时间:每条指令执行结束的时候,此时CPU将INTR置为1
实现(中断隐指令):

具体过程略
中断服务程序要开中断(隐指令中关中断了),具体什么时候开看需求
中断屏蔽技术
对于单重中断服务程序,服务完之后恢复现场后再开中断(防止执行的时候打断)
多重中断服务程序: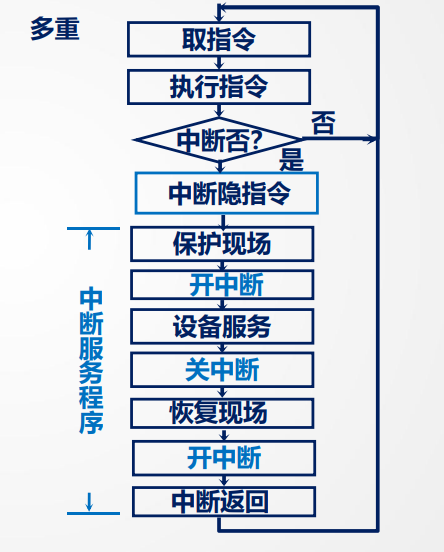
此时保护现场之后就开中断以实现中断嵌套
实现条件:
- 提前设置开中断指令(保护现在之后就设置)
- 优先级别高的中断源有权中断优先级低的中断源
注:在没有高优先级中断低优先级中断实现“立刻抢占”,即中断嵌套时,CPU是在“每条指令结束时”检查是否有新的中断,也就是说,计算机系统中的中断处理机制采用“中断返回后再响应新的中断”的策略,而不是在一个中断服务程序内部立即无条件嵌套进入另一个中断。后面的CPU执行程序的轨迹应注意。
※中断屏蔽字
硬件固定优先级不够灵活。例如,有时希望让磁盘中断临时高于键盘中断。
中断屏蔽字表每一列对应一个屏蔽关系,这样我们可以通过中断屏蔽处理技术改变处理优先级,但是不会修改响应优先级
- 响应优先级:CPU响应各中断源请求的优先次序
- 处理优先级:CPU实际对各中断源请求处理的优先次序
例如:
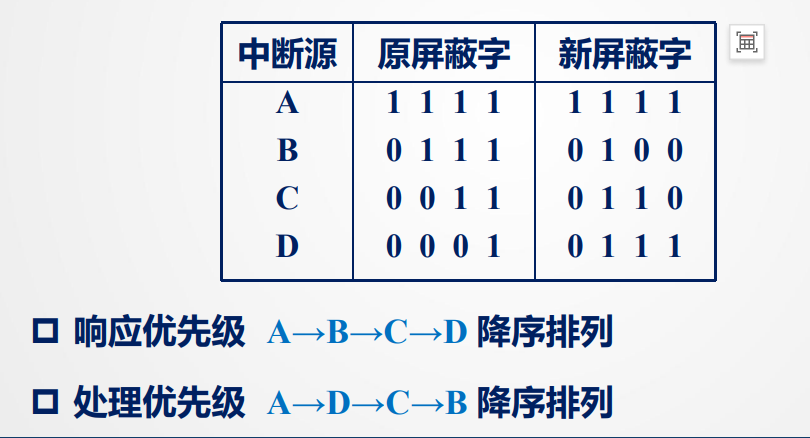
例如C,第2、3列为1表示可以屏蔽B、C的中断请求
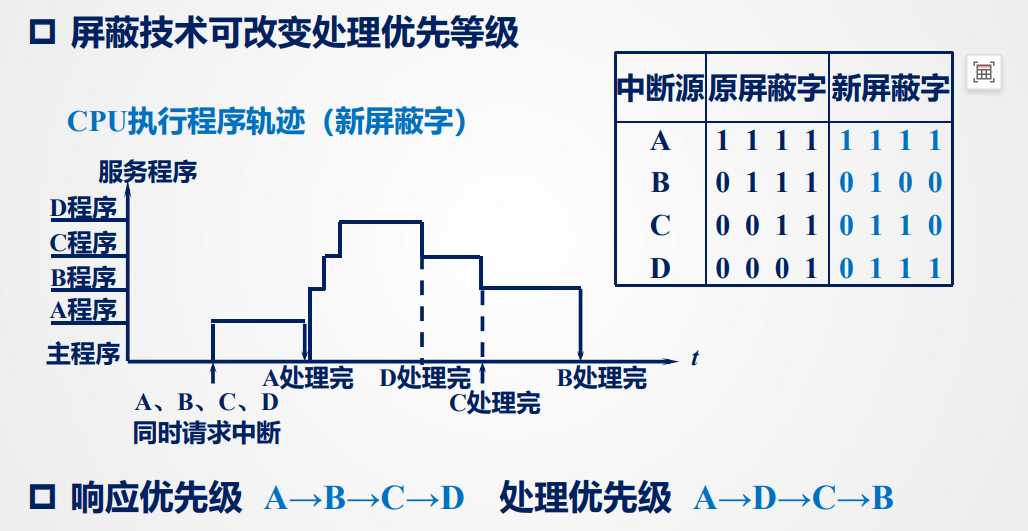
注意画的时候的小缝隙和小阶梯,缝隙正如前面的中断屏蔽技术所述,小阶梯表示同时请求时的响应顺序。
断点保护:
中断嵌套的断点保护必须满足 后进先出 的原则,通常使用 堆栈 (硬堆栈)来实现。
DMA工作方式
与主存交换数据的三种方式:
- 停止CPU访问主存
- 周期挪用(周期窃取)
- DMA和CPU交替访问,不需要时申请建立和归还总线的使用权
DMA接口的功能:

工作流程:
- 预处理:CPU参与
- 数据传送:CPU不参与,由DMA控制器完成
- 后处理:中断形式,CPU参与
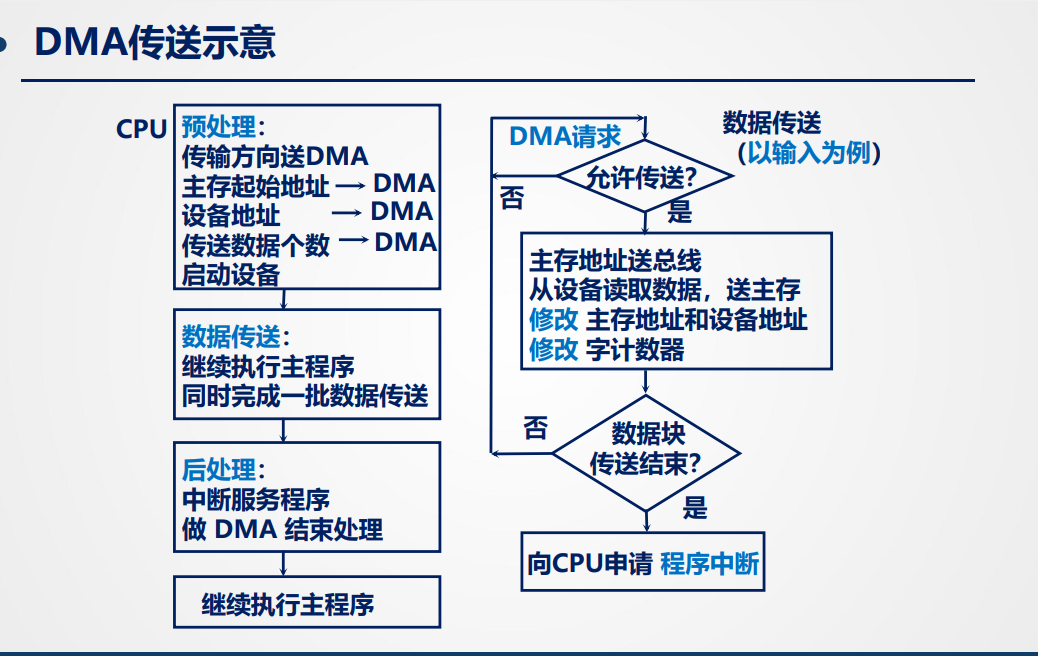
传送过程略
后处理:
- 校验输入主存的数是否正确
- 决定是否继续使用DMA,重新初始化DMA,或者停止设备
- 测试传送过程是否正确,错则转诊断程序
DMA接口与系统的连接方式:
- 具有公共请求的DMA请求
- 独立DMA请求
DMA接口类型:
- 选择型
- 多路型
比较
对于I/O性能的度量,不存在完美的度量标准,不同标准有可能相互冲突,例如 响应时间和吞吐量。
典型外设:
键盘布局的由来是为了降低打字速度
计算机中除主机外的其余部分,称为外部设备( I/O 设备、 外设)
分类
人机交互设备:键盘、鼠标、打印机、显示器…
信息存储设备:磁盘、光盘、磁带…
机–机通信设备:调制解调器、A/D、D/A…
辅助存储器
特点:
容量大、成本低、速度慢、非易失性、不直接与 CPU 交 换信息
分类:
磁表面存储器、光存储器
容量计算


五、计算方式
数的表示
无符号数和有符号数
数在运算时,均存放在寄存器中,寄存器的位数即机器字长。
- 没有符号的数,寄存器的每一位存放的都是数值。
- 数字的极性也用二进制数表示,0代表正数,1代表负数,符号位放在数字的前端。 这种把符号“数字化”的数,叫做机器数,而数字原本的带 (有正负号的)值称为真值。

通常用 " x “表示真值,n为整数/小数的位数
原码反码补码移码
原码:
符号位0为正,1为负
整数的符号位与数值位用逗号分隔,小数的符号位与数值位用小数点分隔。
整数:
$$ [x]_{\text{原}}= \begin{cases} 0,\ x & 2^n>x\ge 0 \\ 2^n-x & 0\ge x>-2^n \end{cases} $$小数:
$$ [x]_{\text{原}}= \begin{cases} x & 1>x\ge 0 \\ 1-x & 0\ge x>-1 \end{cases} $$如x = -1110 则 [ x ] 原 = 2^4 + 1110 = 1,1110
注意 +0 与 -0 的原码不同
优点:表示方法简单 缺点:加减、结果符号复杂
反码:
常用作求补码的过渡(下图x为真正,n为整/小数的位数)
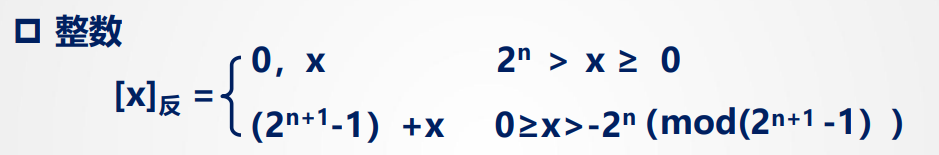
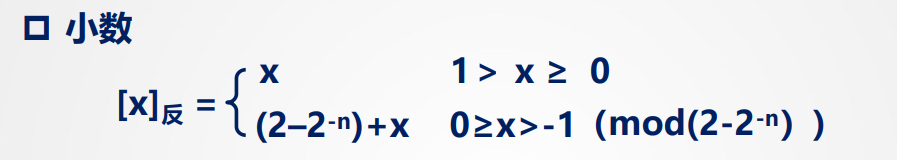
其实就是原码的: 符号位不变,数值位按位取反,逗号将符号位和数值部分隔开不变
如 [x]_反 = 1,1110 -> x原码为1,0001,真值为-0001(二进制)
补码:
反码的末位 + 1,或者原码处符号位按位取反,直到最后一个1的时候不取反
整数:
$$ [x]_{\text{补}}= \begin{cases} 0,\ x & 2^n>x\ge 0 \\ 2^{n+1}+x & 0>x\ge -2^n \end{cases} $$小数:
$$ [x]_{\text{补}}= \begin{cases} x & 1>x\ge 0 \\ 2+x & 0>x\ge -1 \end{cases} $$补码可看作“离进位的距离”,由于符号位为1,需要在数值位进位才能把符号为的1进位,进位后变成正数,所以若是正负数的补码相加,符号位不进位,则达不到进位要求,即负数离进位的差距比正数能弥补的差距大,故符号位仍然是1,总体为负数。
注:补码能比反码多表示一位负数(1,000…时),因为此时+-0的补码相同,而-0的原先的原码被拿去表示负数
移码:
问题:补码表示很难直接判断其真值大小
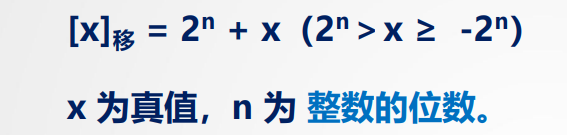
移码与补码的数值部分相同,符号位相反,+-0移码相同
其实就是把补码符号位取反然后把符号位算进数值位来比较了,要注意移码一般是基于补码算的。
BCD码:
哦对了
就是用二进制表示十进制,基本上都8421BCD码(除此还有2421、5211):
8421BCD用每四位二进制表示十进制,如0100 1001 表示 49
与二进制通过“满五进三”和“满八减三”转换,有兴趣自己了解
定点数,浮点数
定点表示
小数点按照约定的地方标出,对于纯小数与纯整数来说:

而整数 + 小数符号位在整数部分,整数和小数部分在定点表示中不分开表示
浮点表示
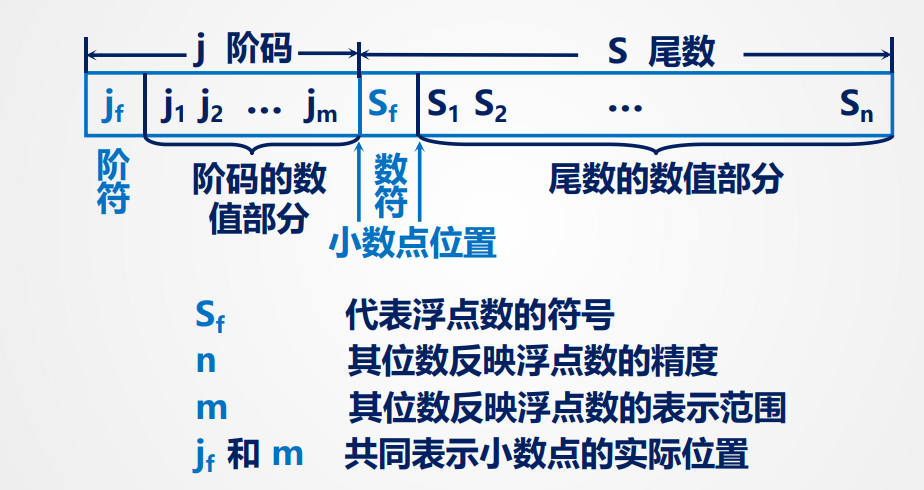
一般形式:
$$ N = S*r^j $$S表示位数,j 表示阶码,r 表示基数(基值)
- 基值r :阶码部分表示的放大/缩小的倍数,一般是2的次方,绝大部分情况下r = 2,也就是阶码部分变化1尾数部分变化两倍
- 阶码j :分为阶符和数值部分,阶符为符号位,负缩小正放大,符合常识
- 尾数S:分为数符和数值部分,数符和数值部分中是小数点
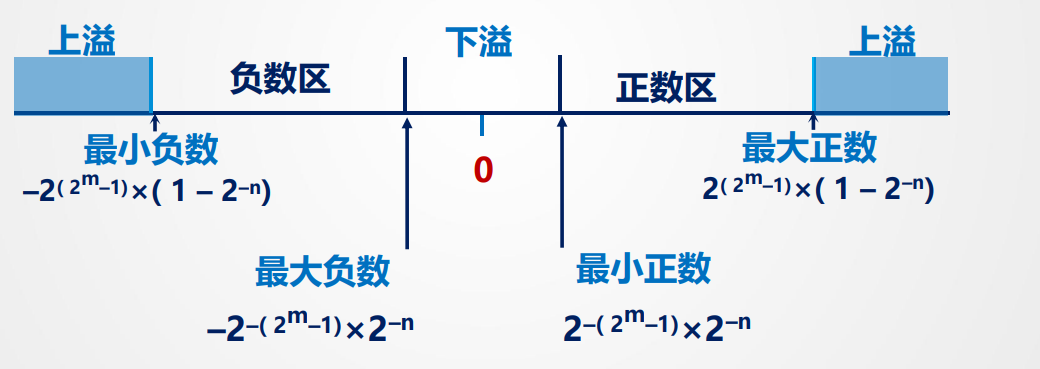
表示范围:
- 上溢:阶码 > 最大阶码 按中断溢出处理
- 下溢:阶码 < 最小阶码 按机器0处理(太小了)
- 表示范围为:
float:32位精度,9 + 23
double :64位精度,12 + 52
隐藏位问题一般不考虑吧 //TODO
规格化表示:
要求尾数的高位至少从某位开始必须为1(r = 2 时为最高位),否则尾数继续放大
注:当r = 2^a时,规格化表示时的尾数的数值部分的前a位不能全为0

对后面的计算有重要作用
比较:

另外,整数可在最大值和最小值之间表示所有数,但是浮点数通常是一个无法表示的数的近似。(实数无穷多个)
机器零:
- 尾数为0时不论阶码什么值都按机器零处理
- 当浮点数阶码等于或小于它所表示的最小数 时,不论尾数为何值,按机器零处理
定点数运算
定点数移位运算
一般使用的是“数相对小数点移动的位”而非小数点移动的位
移位规则
空位处理:
处理表:
即:凡是右移移补符号位的数,左移只有反码负数补1,也可以从定义记
移出有效位后果:左移结果出错,右移丢失精度
算术移位和逻辑移位
算数移位:有符号数的移位
逻辑移位:无符号数的移位
逻辑左移:低位补0,高位移丢
逻辑右移:高位补0,低位移丢
定点数加减和溢出判断
对于有符号整数的加减运算,现代计算机普遍使用补码表示法进行计算
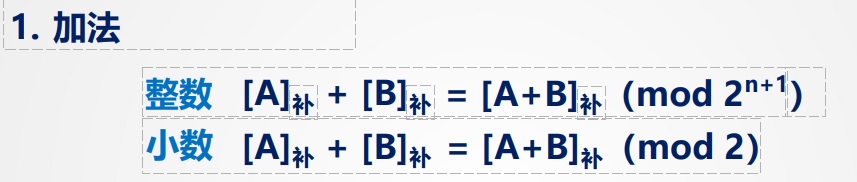
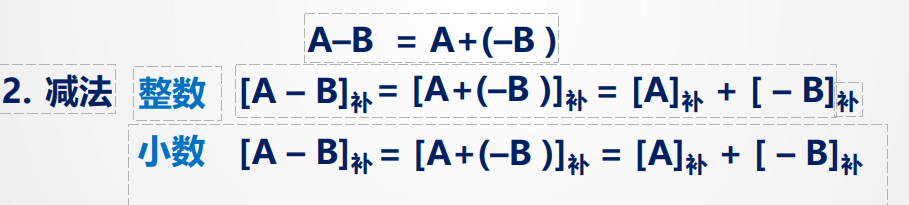
此时,连同符号位一起相加,符号位产生的进位自然丢掉
溢出:
运算结果超出计算机字长所能表示范围的情况,称为溢出。(原因之一符号位一起计算导致)
符号相同时的一位符号位判断溢出:
两个数符号相同,结果的符号与原数符号不同,即为溢出。
任意符号两数的一位符号位判断溢出:
两个数符号位可以不同,如果运算结果中最高数值位的进位与符号位的进位不同,则发生了溢出。
两位符号位判断溢出:
参加运算的两个数,均采用双符号位(称为变形补码),如结果的两位符号位不同,则发生了溢出。
且无论是否发生溢出,双符号位的高位总代表真正的符号
※定点数乘法
定点数一位乘
原码一位乘:
核心思想:(lxc PPT)
- 右移代替左移。部分积相加时最低位只用一次,此位将来不再参与运算,因此可将部分积寄存器右移一位
- 乘数的各个位从右向左均只用一次,最低位不再使用,因此部分积右移时,乘数寄存器也可右移一位,即可用乘数寄存器的最高位接收部分积移出的位。
- 进行正常的二进制加法
特点:
- 用移位的次数判断乘法是否结束
- 绝对值运算
- 使用了逻辑移位(无符号数移位)
补码一位乘:
- 补码与真值的转换关系为:
当X < 0时:
$$ [X]_补=1.X_1X_2X_3...=2+X $$即
$$ X=[X]_补-2=1.X_1X_2X_3-2=-1+0.X_1X_2X_3 $$补码右移:
连同符号位将数右移一位,并保持符号位不变,相当于乘 1/2
校正法:
由Y的补码的最低位乘X的补码,然后右移一位,再加Y的补码的次低位乘X的补码,然后接着右移一位,再加…直到Y补码的最高数据位乘X补码,最后右移一位,得到XY积的补码

也就是,当乘数(y)为正时,不需要矫正,只需用X的补码乘Y的数值部分
当乘数为负,需要矫正,需要在结尾 + [ -X]补
注:
- 过程中用了两个符号位
- 乘数用Y的补码
PPT中的例子:
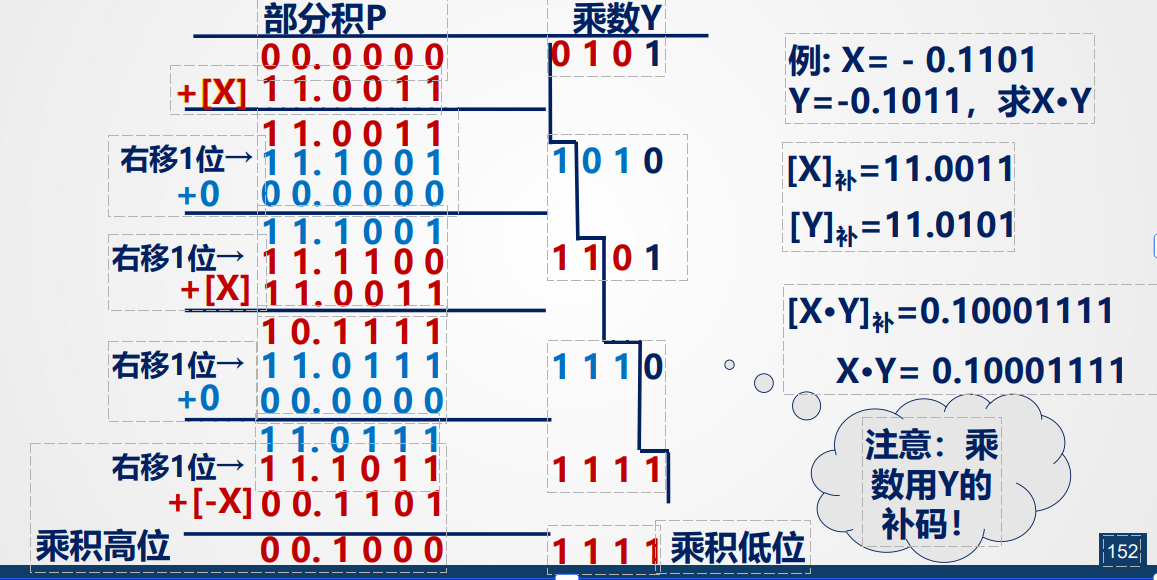
Booth法
$$ [X \cdot Y]_{补} = [X][(Y_1 - Y_0) + (Y_2 - Y_1)2^{-1} + \cdots + (Y_n - Y_{n-1})2^{-(n-1)} + (0 - Y_n)2^{-n}] $$即(注意Y_n+1为0,是为了做公式添的末位0,此时从0加到N,共N+1项):
$$ [X \cdot Y] = [X] \cdot \sum_{i=0}^{n} (Y_{i+1} - Y_i)2^{-i} $$此时N+1项相加,最高项权为1,注意是低位减高位,此时有三种不同的可能性,根据可能性做:
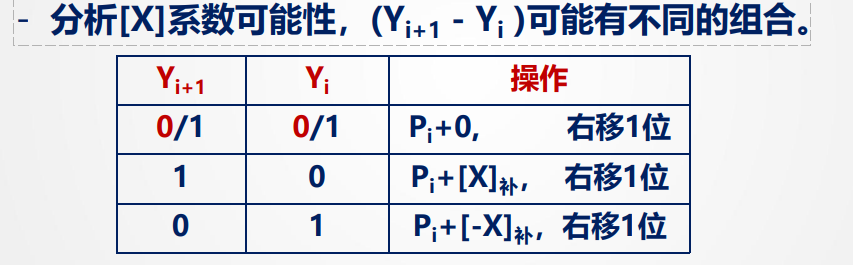
也就是说,后项减前项,得1则+[X]补,得0加0,得-1加 +[-X]补,然后每比一次右移一位
PPT的例子:

两种方法都使用了两位符号位和补码右移
定点数两位乘
两位乘技术可减少部分积个数、提高乘法速度
注:此时符号位为三位
原码两位乘
两位乘数有四种组合,其中1 1 相当于 3*X,部分积P_i + 3X并右移两位
由于不能通过移动获得3X,故采用进位C记录,由于3X = 4X - X,此时先-X,右移两位后 +X(也就相当于吧这个+X放大为四倍),则可实现+3X
在下表中可以看到,当控制位两个Y表示的数+C为3时,需要保证进位为1,并此时-X,当两个Y表示数+C = 4(4X)时,相当于右移两位后+1(+X),故操作无需-X,并将1 -> C
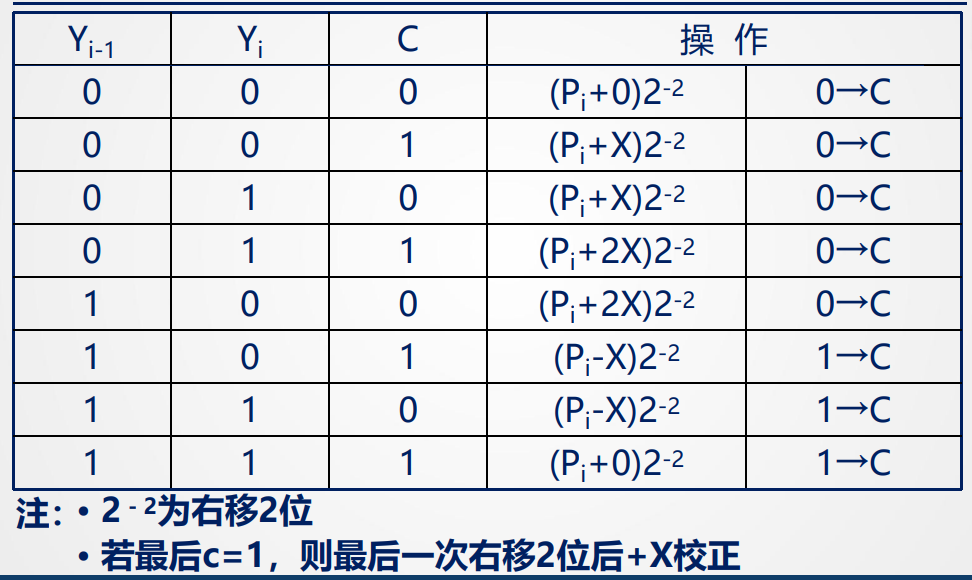
lxc 的PPT样例

由前面的布斯公式有
$$ [P_{i+1}]_{\text{补}} = \left\{ [P_i]_{\text{补}} + (Y_{n-i+1} - Y_{n-i})[X]_{\text{补}} \right\} 2^{-1} $$$$ [P_{i+2}]_{\text{补}} = \left\{ [P_{i+1}]_{\text{补}} + (Y_{n-i} - Y_{n-i-1})[X]_{\text{补}} \right\} 2^{-1} $$反正就是得:
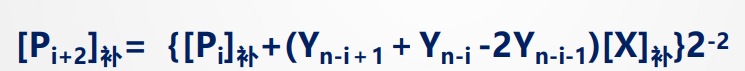
再由Booth法分析系数
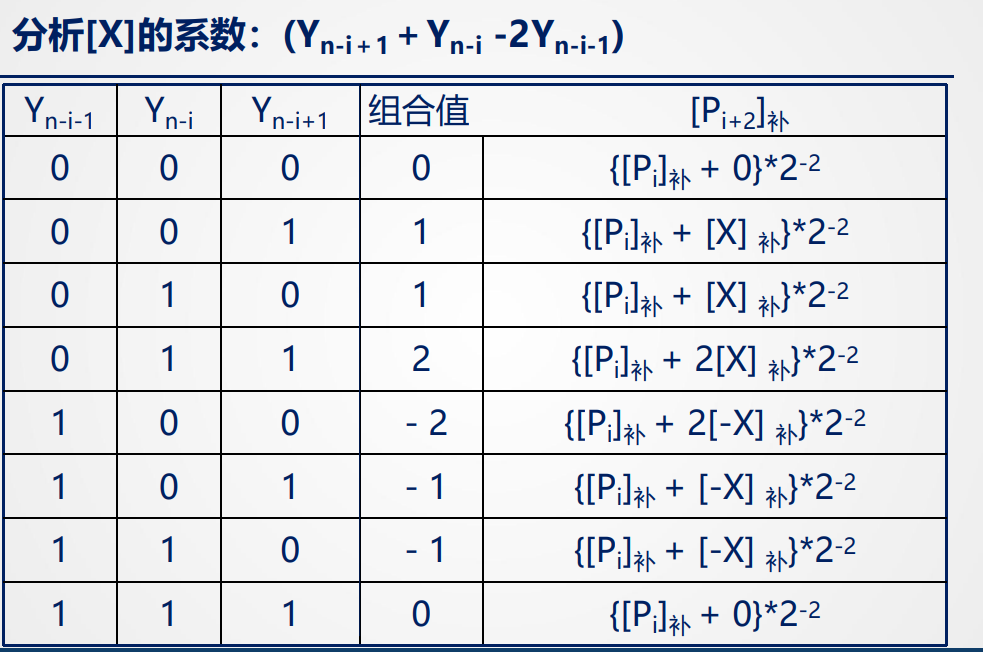
二位乘的次数和控制:
- 乘数是1个符号位+n(奇数)个数据位时,求部分积 (1+n)/2次,且最后一次只移一位。
- 乘数是1个符号位+n(偶数)个数据位时,在乘数后补一个0,然后等同方法1。 或者乘数增加一个符号位,求部分积(1+n/2)次,且最 后一次不需移位。
方法一样例如下:

补位是方法1中补成技术位的位,附加位是为了凑公式的位(如同一位乘的Booth法),此时两位都参与计算,之后剩的自然的丢掉
定点数除法
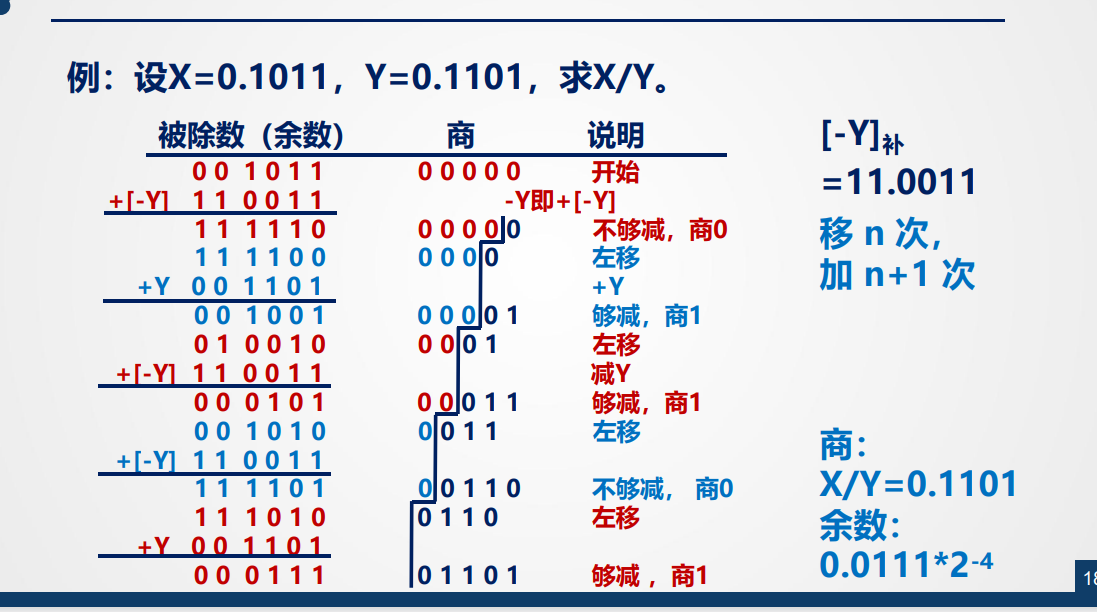
定点原码一位除
恢复余数法
部分余数:指的是每一步求出一位商之后所剩下的余数。
每次都减去除数,如果结果为负数则加回去,然后被除数和商同时左移 1 位。商的符号位由被除数和除数的符号位异或得到。商的最高位可以用于溢出判断,若为 1 说明溢出,无法继续计算。
所谓恢复余数法就是减后若小于0则将部分余数“恢复”,这个“恢复”指的是计算机的行为,实际直观执行过程就是正常的除法过程
- 当差为正:商上1(商写1),不恢复余数,部分余数左移1位。
- 差为负:商上0,恢复余数(部分余数),部分余数左移1位。
问题:速度慢,控制方式复杂
以下是X = 0.1011 Y = 0.1101 时的X/Y:

运算过程中,被除数寄存器不断左移,右侧补零
通过扩展零,让除法器实现2n bit / n bit,可以最终得到n bit商、n bit余数 被除数(或初始部分余数)的左移次数并不需要动态判断,而是由所需的商的有效位数直接决定,固定为 n 次,其中 n是商的二进制位数
加减交替法
本质是是恢复余数除法的一种修正
恢复余数法在被除数是负数时需要加回除数,比较浪费时间。因为恢复余数和下一次试商的过程合起来是 2(R_i+y∗)−y∗,可以化简为 2R_i+y∗,所以可以通过下面的方法来减少这一次恢复的操作:
- 当余数 Ri>0 时,上商 1,做 2Ri−y∗ 操作。
- 当余数 Ri<0 时,上商 0,做 2Ri+y∗ 操作。
即:商为1时,求下一轮余数的方法为左移余数减除数,商为0时, 左移余数并且加除数。 同时,若最后一次上商为0,需恢复余数,即Rn+Y。(此图中就是最后的00 0111,但是最后一次上上不为0)
定点补码一位除
不重要
浮点运算
浮点加减
当
$$ x = S_x \cdot 2^{j_x} , y = S_y \cdot 2^{j_y} $$加减运算步骤:
对阶、尾数相加减、规格化、舍入、判溢出。
对阶:
让阶数变得相同,让尾数可以加减
计算ΔJ= JX -JY,并将**小阶码(正常的小,不是绝对值小)**数的尾数右移︱ΔJ︱位,其阶码值加︱ΔJ︱(前面提到右移丢失精度,但左移出错,当然右移过程中移掉的位可用附加位电路暂时保存)
并注意右移时原码补0,补码补符号位
尾数处理
加减:ΔS = SX ± SY
然后进行规格化以尽可能提高精度,使其做到:

注意r = 2时规格化的最大位要求会有所不同
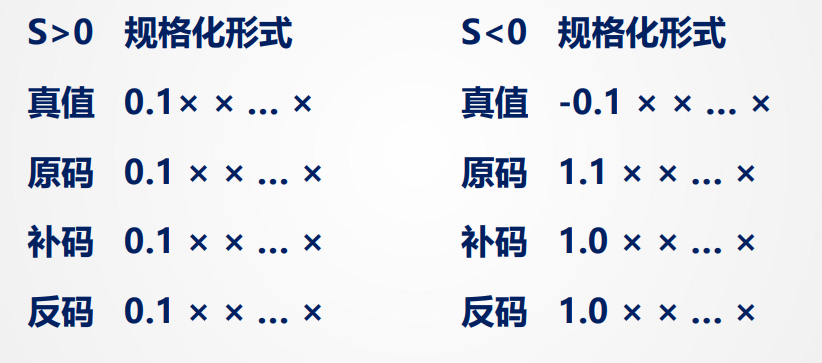
即除了S<0时的反码固定为1,其他的最高位和符号位相反 记住S < 0时候补码反码最高位为0
规格化操作时的规则:
- 右规:结果的两个符号位不同表示尾数结果溢出,右移1 位尾数,阶码J+1
- 左规:结果的两个符号位相同,如是原码且数值位最高位 为0,则左移;如是补码且数值位与符号位相同也需左移。 同时阶码减去移动的位数
舍入
当超过机器位数时,需要将尾数舍入,一般有三种方法:
- 截断法
- 恒置1法
- 0舍1入法
判断溢出
- 阶码下溢,则置运算结果为机器零;
- 阶码上溢,则置溢出标志,报警中断 。
浮点乘法

运算步骤:操作数检查,计算阶码(加减)和尾数(乘除) ,结果规格化、舍入和判溢出
此时涉及到阶码的加减而非简单的变化,需要考虑浮点数的阶码运算
浮点数的阶码运算
阶码通常用补码 或 移码表示
我们已知:[X]移= 2n+X,[Y]补=2n+1+Y
用移码表示阶码:可以使用补移码混合
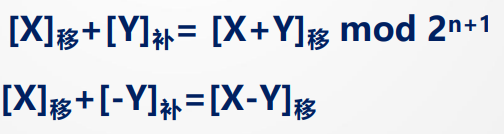
移码加减使用双符号位判断溢出,规格化不变,舍入略
尾数运算
尾数正常相乘(如定点数一般),然后放到小数点后面
浮点除法略
加法器:
半加器、全加器
n位串行加法器、超前进位加法器
ALU算术逻辑单元–进行多种算术运算和逻辑运算
六、指令系统
指令
概述:
计算机执行机器语言程序,组成的程序的每一条指令称作一条 机器指令,一种计算机能够执行的机器指令的集合就是这种计算机的 指令系统
指令字长(可能会变):一条指令的总长度
机器字长:CPU进行一次整数运算能处理的二进制数据的位数
存储字长:一个存储单元中的二进制代码的位数(通常和MDR位数相同)
指令字长回应取指令所需时间
RISC和CISC:
- RISC:精简指令集计算机,指令数量少、每条指令功能简单、长度固定,通常一个时钟周期执行一条指令,典型代表ARM、RISC-V
- CISC:复杂指令集计算机,指令数量多、功能复杂、长度可变,一条指令可能完成多个低级操作(如内存读取+运算+写回),执行需要多个时钟周期。典型代表x86(Intel/AMD 的 CPU)
机器指令格式:
一般包括操作码和地址码两部分
操作码:位数反应机器指令数目,内容反应机器做什么操作
- 长度固定(定长):如RISC,规整、译码简单,灵活性低
- 长度可变(可变长):操作码分散在指令字的不同字段中,控制器设计复杂,但灵活性高
地址码:用来指定地址(操作数、结果、下一条指令的地址)
- 四地址指令
- 三地址指令
- 二地址指令
- 一地址指令
- 零地址指令:来源和结果的存放位置都是隐含指定的,如NOP、HLT、停机、关中断等指令,成就了堆栈计算机在代码密度和编译器友好性上的优势,便于实现虚拟机
操作码扩展技术:
通过操作码扩展技术,能有效缩短指令的平均长度
基本是通过操作码前几位固定的“标志”,来告诉硬件当前指令的操作码是多长,从而也决定了地址字段怎么划分。例如一般使用4位操作码的前15种代表地址指令,最后一种(1111)表示“需要继续解析操作码”
例如:

还可通过其他扩展方法来修改各数量地址的指令数
需注意:
不允许短码是长码的前缀,各指令操作码不能重复

操作类型
操作数类型:
- 地址:有时地址也需要计算,此时地址也是数据
- 数字:定点浮点
- 字符:ASCII
- 逻辑数据:每一位都代表真(1)或假(0)的布尔类型数 据,这种数字串即为逻辑数
存储方式:
大端小端:小端数据低位存在地址低位,大端反之
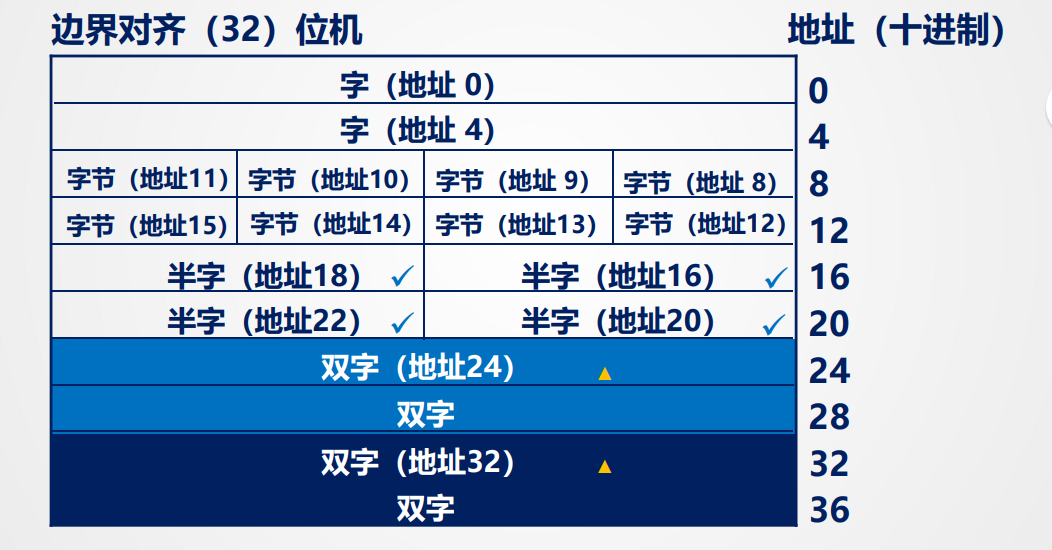
对齐:多字节的数据再存储器中应“边界对齐”,以32位机为例,具体表现为:
- 字节数据可以任意存放
- 半字存放在偶数地址(2的倍数)
- 字存放在末两位地址为0处(4的倍数)
- 双字存放在末三位地址为0处(8的倍数)
也就是起始地址要是自己所占字节的倍数
程序状态字:


操作类型:
1.数据传送
LOAD:把存储器中的数据放到寄存器中
STORE:把寄存器的数据放到存储器中
可以使用MOV表示数据流向
一般用AX、BX等表示寄存器,数字表示存储器
2.运算类
算数:加减乘除,INC,DEC…
逻辑:与或非、异或、位操作
3.移位指令
一般来说有八种
算数移位(左右)、逻辑移位(左右)、(大小)循环(左右)移位
4.转移操作
实现程序执行流的转变,本质改变了PC的值
无条件转移指令: JMP
条件转移
调用和返回(Call 和 Return,配对使用)
Trap和陷阱指令
5.输入输出
对I/O单独编址的计算机,设置有专门的输入输出指令,用来操纵外设。
Callback:
统一编址:I/O占用存储器地址空间,采用不同地址来区分访问对象
独立编址:I/O地址与存储器地址分开,不占用主存,采用不同指令形式来区分访问对象
6.其他
停机指令、空操作指令、开中断指令、关中断指令、置条件码指令等
寻址方式
指令寻址
也就是找下一条欲执行指令的地址
如何确定下一条指令的存放地址?
- 顺序寻址:(PC) +“ 1 ”-> PC(程序计数器),加的数会根据指令字结构改变
- 跳跃寻址:由跳跃(JMP)指令给出,直接变为指向的地址并且不加1
数据寻址
目的:确定本条指令的地址码指明的真实地址
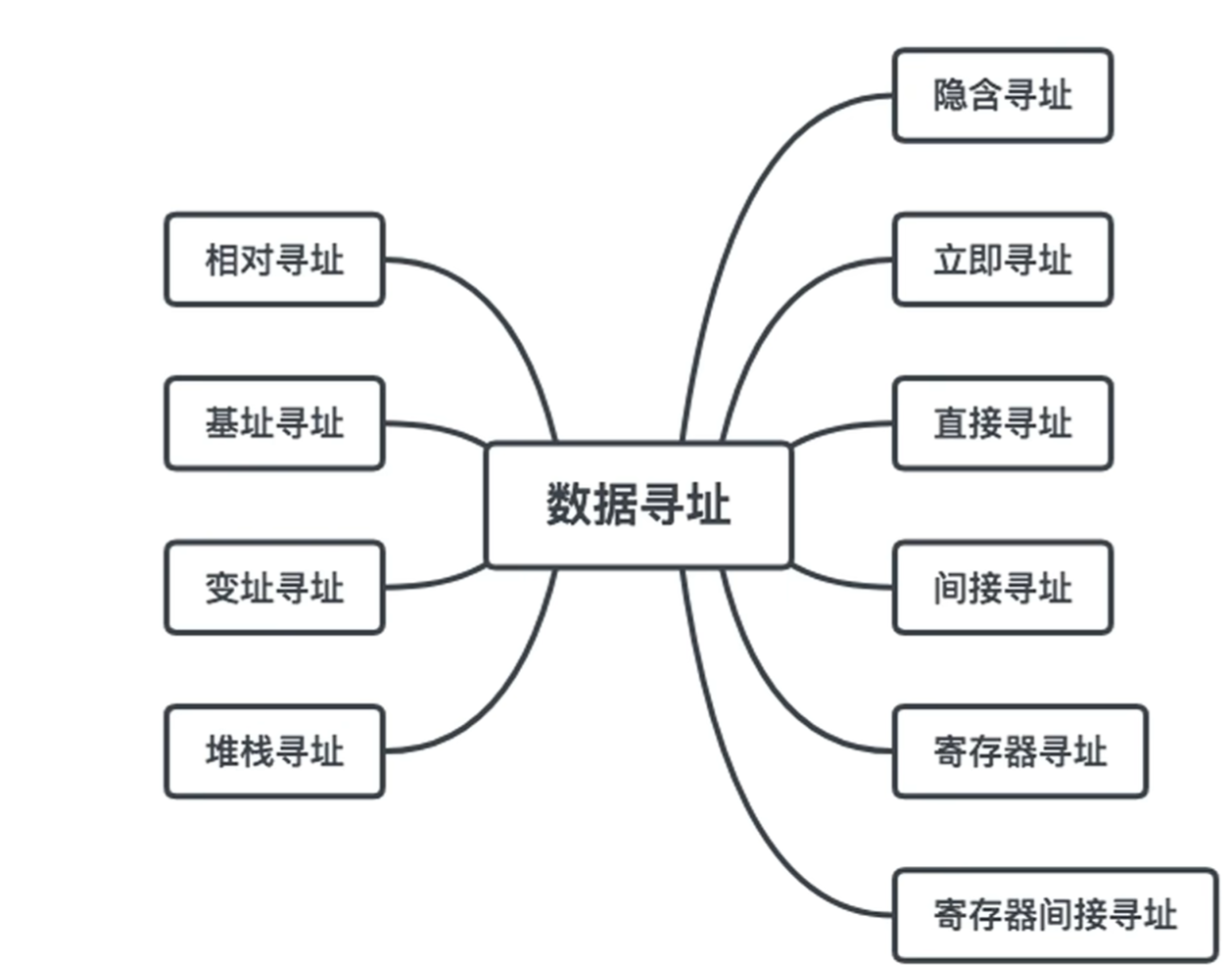
由于数据寻址有多种,为了分辨,需在指令中指出寻址方式,则可在地址码前设置一个寻址方式特征字段(寻址方式位),或纳入操作码中。寻址特征可为0~1001。
| 操作码 | 寻址特征 | 形式地址(A) |
|---|
有效地址 (用EA表示) :操作数的真实地址
形式地址(用A表示 ):指令字中的地址
有效地址由形式地址根据寻址方式来确定,多地址指令需要多个寻址特征,为简化,设后面都是一地址指令,且指令字长 = 存储字长 = 机器字长
( )表示这个地址所指向的存储单元,如(A)
1.直接寻址:
指令字中的形式地址就是操作数真实地址,即EA = A,寻址范围有限
取指令访存一次,执行指令访存一次,不考虑存结果则共访存两次
2.立即寻址:
又称作立即数寻址,形式地址部分不是一个操作数的地址,而是操作数本身。一般采用补码形式
取指访存一次,指令执行阶段不访存,共访存一次,A 的位数限制了立即数的范围
教材的直接寻址特征为”#"
3.间接寻址:
指令的地址字段给出的形式地址不是操作数的真正地址,而是操作数有效地址所在的存储单元的地址,也就是操作数地址的地址。
即EA由A间接提供
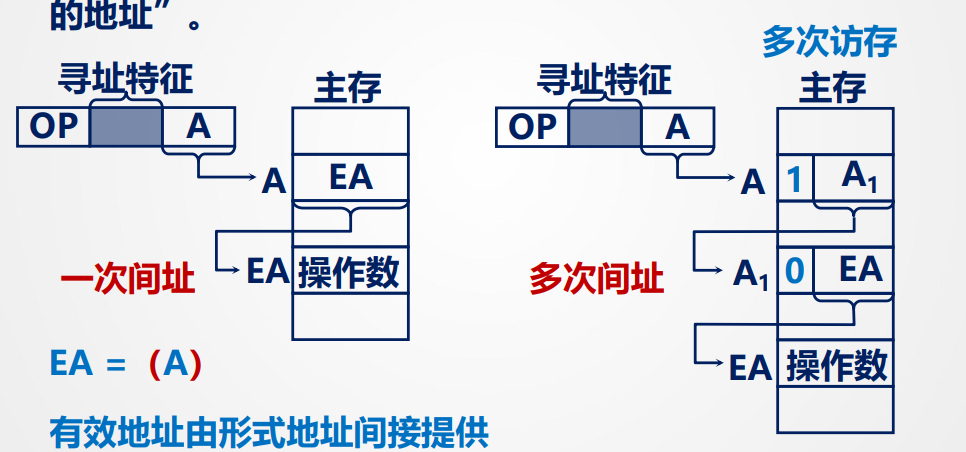
访存:取指令访存一次,执行指令访存两(多)次
优点:扩大寻址范围,因为len(EA) > len(A),同时利于编制程序
缺点:需要进行多次访存(一次间址需两次,后面递增),效率降低
4.寄存器寻址:
在指令字中直接给出操作数所在的寄存器编号,即EA = R_i,其操作数在由R_i所指的寄存器内
访存:取指令访存一次,执行指令只访问寄存器,不访存
优点:指令字短(∵寄存器少)且执行速度块,支持向量/矩阵运算
缺点:贵,个数有限
5.寄存器间接寻址:
指令中的形式地址为寄存器的编号,寄存器的内容是操作数的有效地址。即EA = (R_i)
把3.的第一步换成寄存器而不是主存
取指令访存一次,执行指令访存一次,不考虑存结果则共访存两次
特点:比一般的间接寻址块
6.隐含寻址:
不是直接给出操作数地址,操作数地址通常隐含在操作码(指令)或某个(约定)寄存器中。
只显式给出一颗操作数的地址,另一个地址默认存放在ALU中(如ADD指令)
偏移寻址
以某一个特定地址为起点便宜,区别在于偏移的“起点”不一样
以下指令的执行期间的访存次数都为1
7.基址寻址:
以程序的起始存放位置作为“起点”
指令中的形式地址(A)与基址寄存器(BR)内容之和为有效地址,EA = (BR) + A
显式:采用通用寄存器作为基址寄存器 隐式:采用专用寄存器作为基址寄存器
R作寄存器编号,需要在地址前占用比特位,假设R0作基址寄存器,在程序的执行过程中R0 内容不变,形式地址A可变,A从0开始。
优点:
- 可扩大寻址范围,有利于多道程序
- 基址寄存器内容由操作系统或管理程序确定
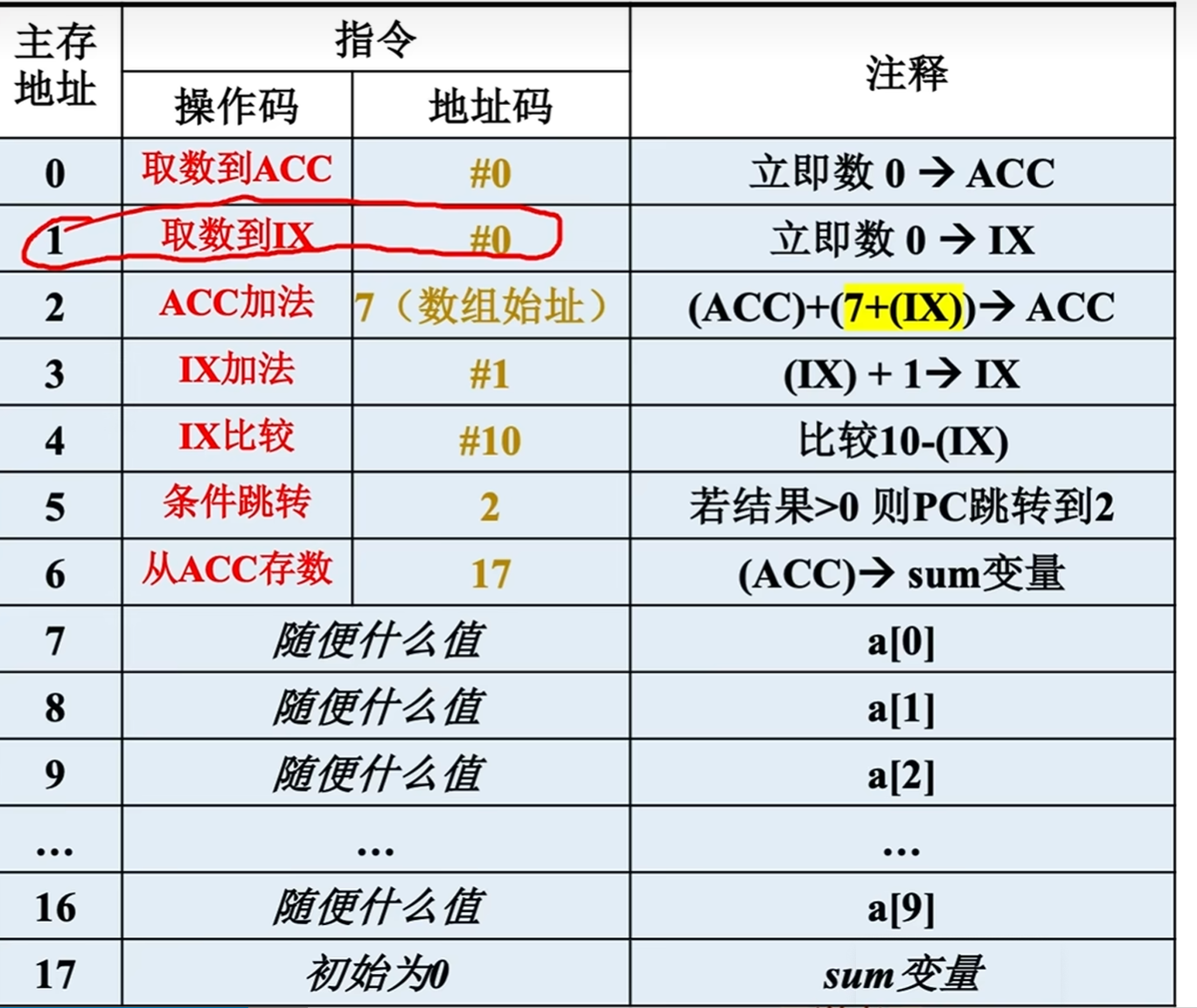
8.变址寻址:
程序员自己决定从哪里作为“起点”
指令中的形式地址与变址寄存器内容之和为有效地址。IX 为变址寄存器,通用寄存器也可以作为变址寄存器
注:与基址寻址不同的是,变址寄存器是面向用户的,在程序执行的过程中,变址寄存器的内容可由用户改变,而形式地址不变(IX作为偏移量,A作为基地址),与7.正好相反,其便于处理数组问题和编制循环程序。
以下是王道的例子:
9.相对寻址:
以程序计数器PC所指地址作为“起点”
有效地址为程序计数器PC的值与形式地址之和,即EA = (PC) + A 其中A是相对于PC所指地址的位移量,补码表示,可正可负
注:此时PC已经自增,因为每次PC取出一条指令都会自动进到下一条指令,即PC + 1(由具体情况判断自增) -> PC,在此基础上再进行的EA = ( PC ) + A 因此相对寻址是相对于下一条指令的便宜,求位移量时应先判断PC自增后的数
优点:便于程序浮动,广泛应用于转移指令
堆栈寻址
10.堆栈寻址
操作数存放在堆栈中,隐含使用堆栈指针(SP)作为操作数地址
即该存储区中被读/写的单元的地址是用一个特定的寄存器给出的,该寄存器就是SP
栈:后进先出、先进后出
种类:
- 硬堆栈:寄存器型(栈底浮动,栈顶不变),执行期间不访存
- 软堆栈:存储器型(栈底不变,栈顶浮动),在内存中划一片区域用于堆栈,执行期间访存一次
工作方式:满栈递减、满栈递增、空栈递减、空栈递增
七、CPU的结构和功能
CPU结构
CPU由控制器和运算器两大部分组成
CPU功能:
- 指令控制:取指令、分析质量、执行指令
- 操作控制:把各种操作信号送往相应的部件(如访存)
- 时间控制:按时间顺序提供应用的控制信号
- 数据加工:算是逻辑运算
- 中断处理
运算器:
对数据进行加工
控制器:
协调、控制计算机各部件执行程序的指令序列
取指令
分析指令:操作码译码,产生操作数的有效地址
执行指令
中断处理
运算器基本结构:
- 算术逻辑单元ALU:用于算数与逻辑计算
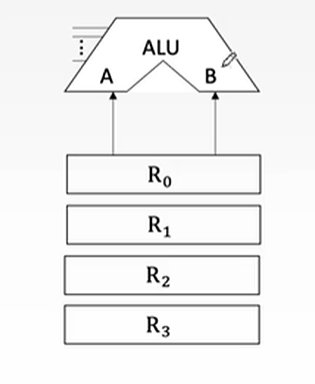
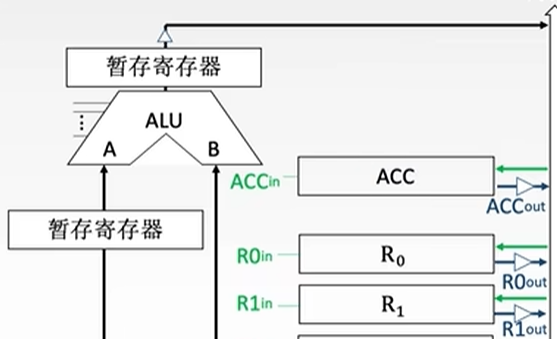
- 通用寄存器组:如AX、BX、CX(也可用R0、R1、R2等表示)、SP等,用于存放操作数,可以用作ALU的输入,SP是堆栈指针,用于指示栈顶地址。
- 暂存寄存器:在ALU下,用于暂存从主存读来的数据,这个数据不能存放在通用寄存器中,否则会破坏原有内容。
- 累加寄存器ACC,是一个通用寄存器,用于赞数存放ALU运算结果的信息,用于实现加法运算
- 程序状态字(标志)寄存器(PSW):保留由算术逻辑运算指令或测试指令的结果而建立的各种状态信息,如溢出标志,进位标志、零标志等,这些位参与并决定微操作的形成
- 移位器:对运算结果进行移位运算(如乘法)
- 计数器:控制乘除的操作步数
选择哪个寄存器可向ALU传输数据
直接用导线连接的情况下,有两种方法: 1.用多路选择器根据控制信号选择一条路输出 ; 2.使用三态门控制每一路的输出
无冲突,性能高,实现困难
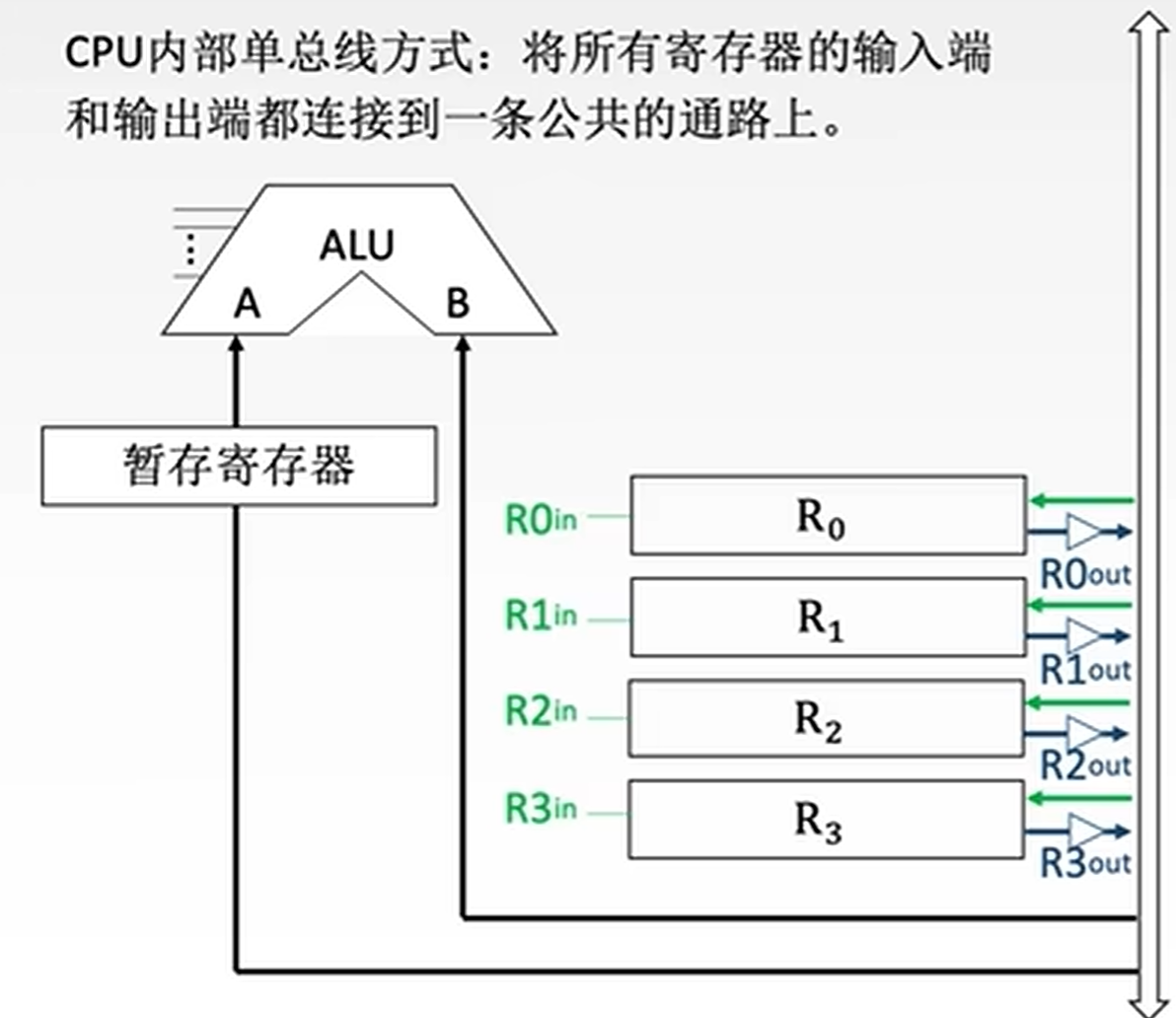
CPU内部单总线方式:所有寄存器的IO端都连接到一条公共通路上
结构简单易实现,性能较低,有冲突
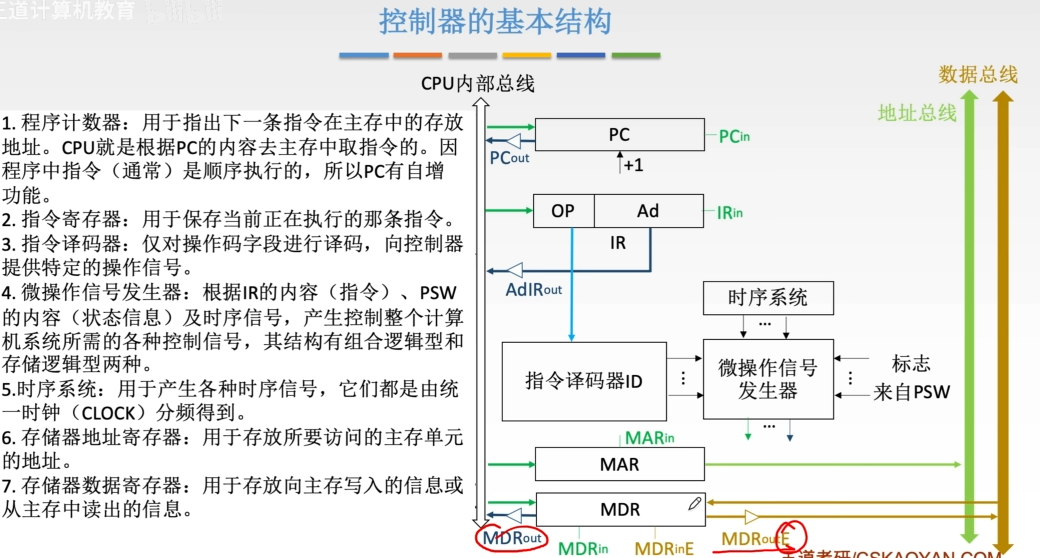
控制器基本结构:
CPU的工作
指令周期
指令周期:取出并执行一条指令所需的全部时间
指令周期包括(指令周期的长度)
- 只有取指周期的指令周期: 取指令PC + 1,并包括对指令译码
- 有取指和执行周期的指令周期
- 具有间接寻址的指令周期(取有效地址)
 注意:直接寻址不在间址周期执行,如果指令采用直接寻址,在取指周期CPU 在拿到指令的同时,也就从指令的地址码字段直接获取了操作数的内存地址。
注意:直接寻址不在间址周期执行,如果指令采用直接寻址,在取指周期CPU 在拿到指令的同时,也就从指令的地址码字段直接获取了操作数的内存地址。 - 带有中断周期的指令周期

机器周期:
指令周期常常用若干机器周期来表示,机器周期又叫CPU周期(上面两图的每个周期都是一个CPU周期)
一个机器周期又包含若干个时钟周期(也称CPU时钟周期、节拍),他是CPU操作的最基本单位
机器周期的确定:以完成最复杂、最慢指令功能的时间为准 或 以访问一次存储器的时间为基准
CPU主频:3.0Ghz,表示CPU每秒钟可以发出3.0G次时钟周期
每个指令周期内的机器周期数可以不等,每个机器周期内的节拍数也可以不等
时钟周期:
将一个机器周期分成若干个时间相等的时间段,每段称为一 个时钟周期(节拍、状态)
时钟周期是控制计算机操作的最小单位时间。
用时钟周期控制微操作命令,每个时钟周期产生一个或几个 微操作命令。
判断处于哪个周期:
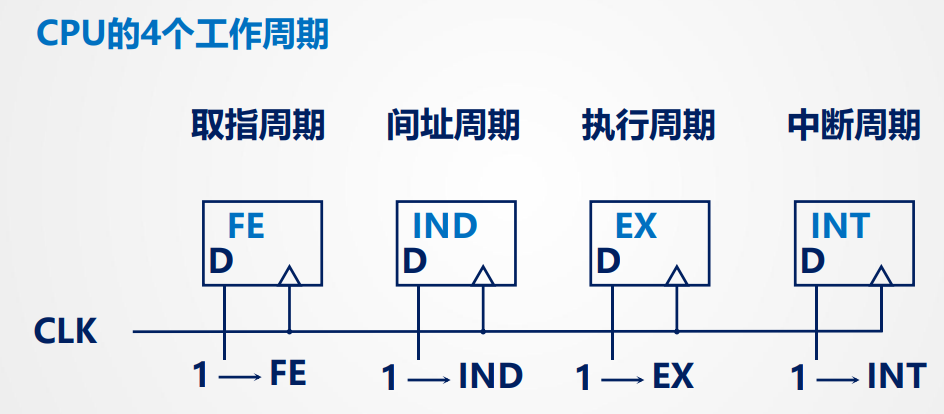
每个周期设置一个对应的触发器
指令周期的数据流
基本概念:
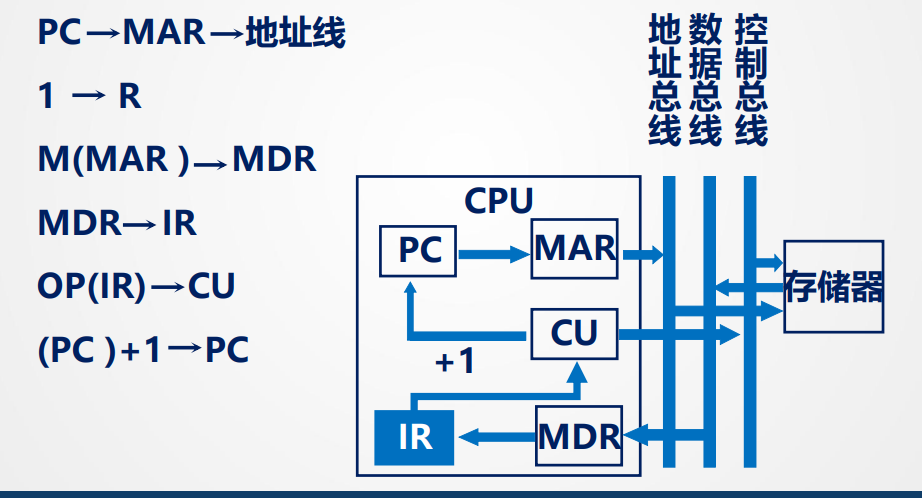
- PC:程序计数器,存放当前将要执行的指令在内存中的地址
- MAR:存储器地址寄存器:用于存放要访问的内存单元的地址
- MDR:存储器数据寄存器:用于暂存从内存读出的数据/将要写入的数据或指令
- 1 -> R/W :发出读/写命令
- M(MAR):主存中由MAR指向的地址单元的内容本身
- IR:指令寄存器:用于存放当前正在执行的指令(包括操作码和地址码)
- OP(IR):IR中的操作码字段,只是此指令要做什么操作
- AD(IR):IR中的地址码字段
- CU:控制单元,CPU的指挥中心
- EINT:允许中断触发器,为1表示CPU开中断,0表示关中断
- SP:堆栈指针
取指周期:
下图很清晰:
间址周期:
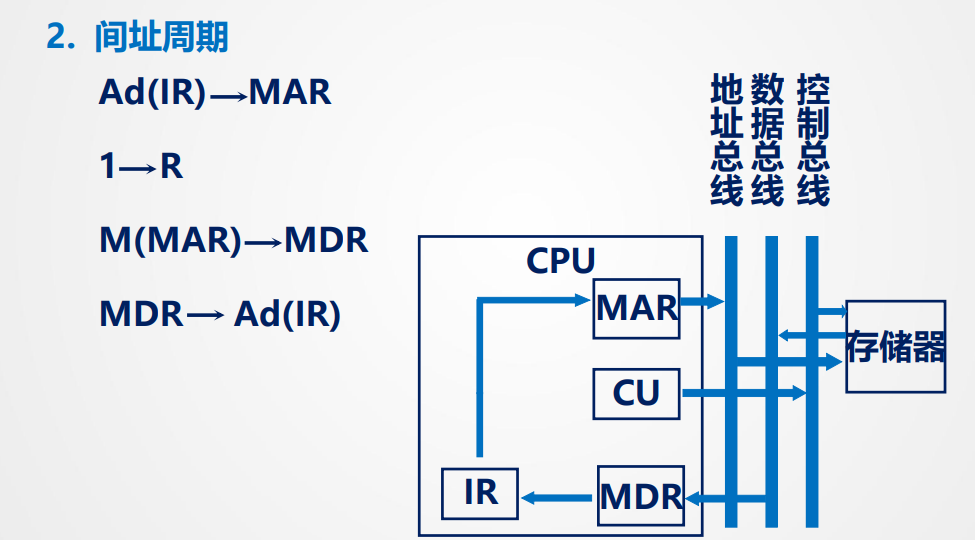
已经有了操作码了,直接MDR -> (AD)IR覆盖掉形式地址即可
执行周期
其实根据IR中的指令字的操作码和操作数通过ALU产生结果,不同指令执行周期操作不同,因此没有统一的数据流向
1.非访存指令:

2.访存指令:
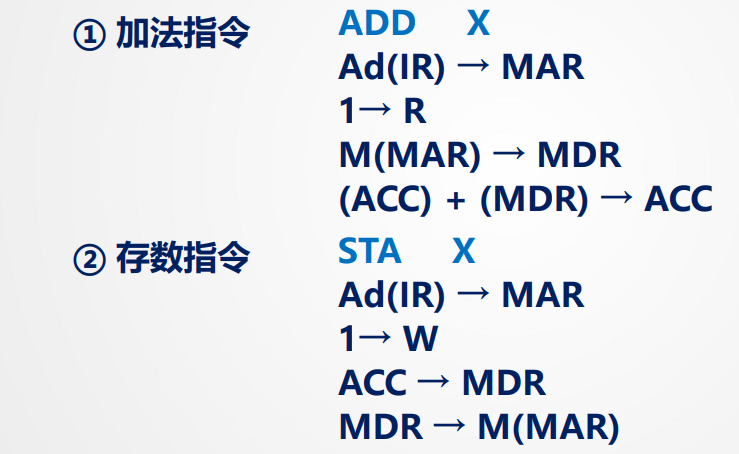

3.转移指令:

中断周期:
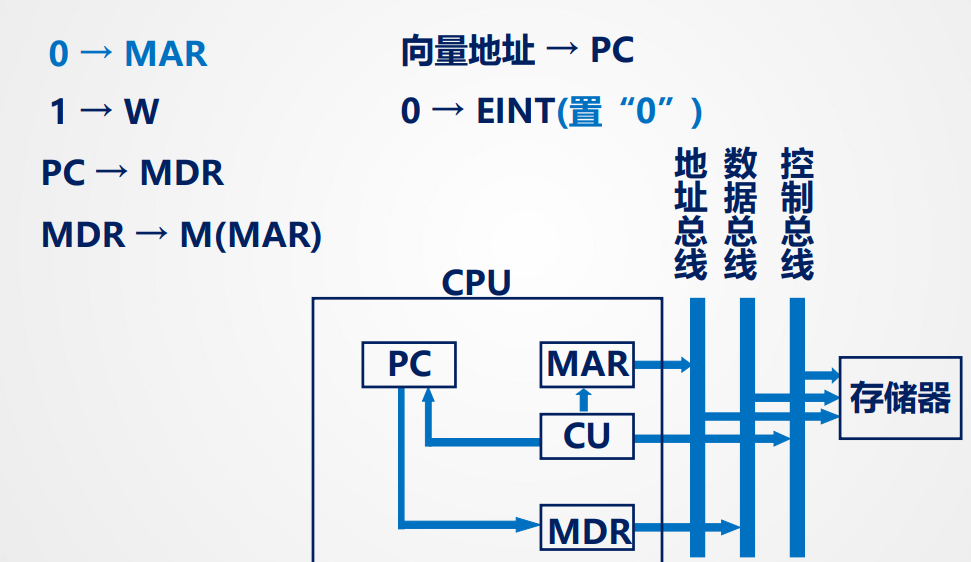
本质都是:寄存器与寄存器之间,寄存器和主存之间,寄存器和ALU之间
指令执行方案:
1.单指令周期:
所有指令选用相同的执行时间完成
指令之间串行,且短时间指令被拖慢。因此比较低效
2.多指令周期
指令串行,单可选用不同个数的时钟周期来完成不同指令,需要更复杂的硬件设计
3.流水线方案:
每个时钟周期启动一条指令,尽量让多条指令同时运行,但各自在不同的执行步骤,指令之间并行执行。
控制信号:
数据通路
数据在功能部件之间传送的路径
基本结构:
- 不采用CPU内部总线的方式
- 采用CPU内部总线的方式
细则略
控制方式:
微操作:微操作是执行一条指令时的最基本、不可再分的原子操作。
控制方式:产生不同微操作命令序列所用的时序方式
1.同步控制方式:
任一微操作均由统一基准时标的时序信号控制。
- 使用定长机器周期:以最长的微操作序列和最繁的微操作作为标准,机器周期内节拍数相同。
- 采用不定长的机器周期:机器周期内节拍数不等。
- 采用中央控制和局部控制相结合的方法。局部控制的节拍宽度与中央控制的节拍宽度一致。
2.异步控制方式:
无基准时标信号
无固定的周期节拍和严格的时钟同步
采用应答方式
3.联合控制:
同步与异步结合
4.人工控制:
看不懂

流水线技术:
PPT吹水部分:如何提高机器速度?

并行

指令流水:
设指令的执行分为六个阶段,则理论可作N级流水,以下是指令六级流水样例:

影响指令流水效率加倍的因素:
- 执行时间 > 取指时间
- 条件转移指令对指令流水的影响。必须等上条指令执行结束,才能确定下条指令的地址。
性能判断
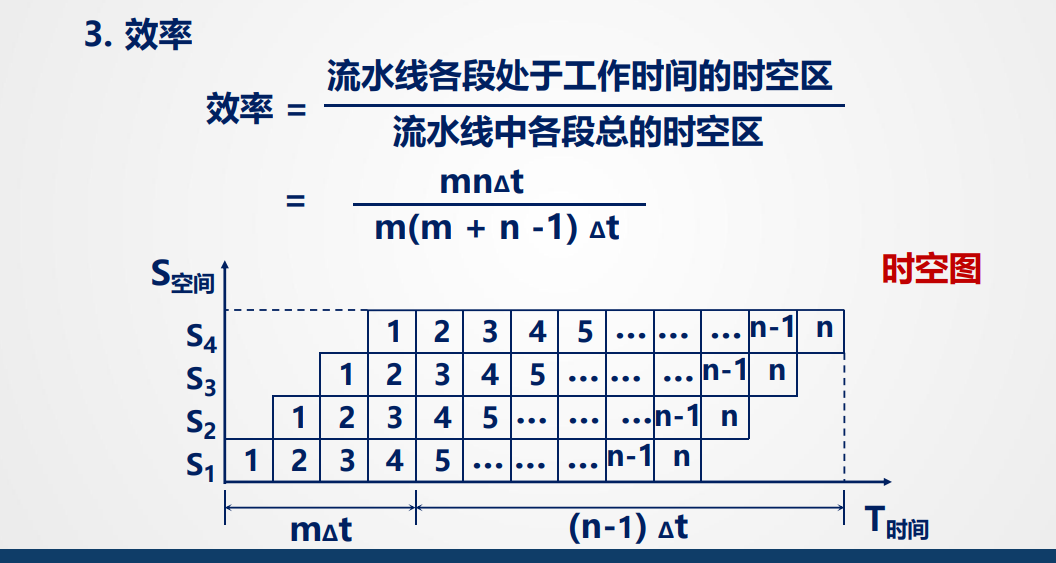
1.吞吐量:
单位时间内流水线所完成指令或输出结果的数量
设 m 级的流水线,各段时间为Δt,连续处理 n 条指令的吞吐率(即实际吞吐率)为
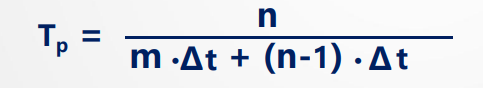
最大吞吐率:
$$ T_{\text{pmax}} = \frac{1}{\Delta t} $$2.加速比S_p
m 段的流水线的速度与等功能的非流水线的的速度之比
设流水线各段时间为 Δt,在:
- 完成n条指令在m段流水线上共需:T = m·Δt + (n-1)·Δt
- 完成n条指令在等效的非流水线上共需:T ′ = n(m · Δt)
则: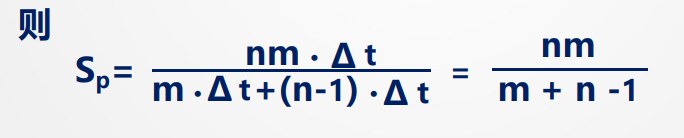
3.效率:
流水线中各功能段的利用率。
产生原因:由于流水线有建立时间和排空时间,因此各功能段的设备 不可能一直处于工作状态。
图一看就懂:
流水线的结构:
- 指令流水线结构
- 运算流水线结构
流水线相关问题
流水线停顿问题:
当相近指令之间出现某种关联,使指令流水出现停顿,影响效率。
问题相关:
1. 结构相关
不同指令争用同一功能部件产生资源冲突
解决方法:
- 后续指令停顿(不推荐)
- 指令存储器和数据存储器分开,多部件
- 指令预取技术 (适用于访存周期短的情况)
2.数据相关
不同指令因重叠操作,可能改变操作数的读/写访问顺序。根本原因是允许速度不同导致的,数据相关分为3种类型:
- 写后读(RAW):后一条指令要读一个寄存器,而前一条指令要写这个寄存器。可能会由于某种原因(如顺序不对、写回在取数后面),后一条会读到旧值
- 读后写(WAR):后一条指令要写一个寄存器,而前一条指令要读这个寄存器。可能会导致先写后读
- 写后写(WAW):两条指令先后写同一个寄存器。流水线中如果前一条写回较晚,后一条写回较早,会导致最终结果错误(后写的值被前写覆盖,比如乘法比加法花时间长,导致加法后执行但先返回)
解决数据相关的其他方法:
- 指令静态调度
- 指令动态调度:指令乱序执行
3.控制相关
由指令转移引起,比如循环判断语句,后一句要先等前句判断才能确定是否执行
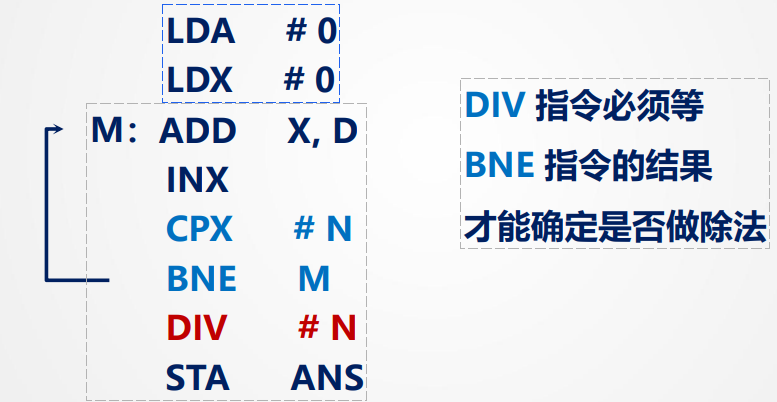
解决方法:分支预测法
由于大部分循环都会符合循环条件,通过预测分支的方向和目标地址,让流水线提前取指和执行后续指令。若预测正确,流水线无停顿;若预测错误,产生分支惩罚,需恢复正确现场。
多发射技术:
超标量技术
- 每个时钟周期内可并发发射多条独立指令,配置多个功能部件。
- 不能调整指令的执行顺序:通过编译优化技术,把可并行执行的指令搭配起来。
超流水线技术
- 在一个时钟周期内再分段,在一个时钟周期内一个功能部件使用多次
- 不能调整指令的执行顺序,靠编译程序解决优化问题
超长指令字技术
- 由编译程序挖掘出指令间潜在的并行性,将多条能并行操作的指令组合成一条
- 具有多个操作码字段的超长指令字(可达几百位)
- 采用多个处理部件